
1 item has been added to your cart.
Last updated: 18 October 2012

Centre for Econometric Analysis
Cass Business School
106 Bunhill Row
London EC1 8TZ
United Kingdom
Applied scientists, especially public health scientists, frequently want to know how much good can be caused by a proposed intervention. For instance, they might want to estimate how much we could decrease the level of a disease, in a dream scenario where the whole world stopped smoking, assuming that a regression model fitted to a sample is true. Alternatively, they may want to compare the same scenario between regression models fitted to different datasets, as when disease rates in different subpopulations are standardized to a common distribution of gender and age, using the same logistic regression model with different parameters in each subpopulation. In statistics, scenarios can be defined as alternative versions of a dataset, with the same variables, but with different values in the observations or even with noncorresponding observations. Using regression methods, we may estimate the scenario means of a Y-variable in scenarios with specified X-values and compare these scenario means. In Stata Versions 11 and 12, the standard tool for estimating scenario means is margins. A suite of packages is introduced for estimating scenario means and their comparisons using margins together with nlcom to implement Normalizing and variance–stabilizing transformations. margprev estimates scenario prevalences for binary variables. marglmean estimates scenario arithmetic means for non-negative valued variables. regpar estimates two scenario prevalences, together with their difference, the population attributable risk (PAR). punaf estimates two scenario arithmetic means from cohort or cross-sectional data, together with their ratio, the population unattributable fraction (PUF), which is subtracted from 1 to give the population attributable fraction (PAF). punafcc estimates an arithmetic mean between-scenario rate ratio for cases or nonsurvivors in case–control or survival data, respectively. This mean rate ratio, also known as a PUF, is also subtracted from 1 to estimate a PAF. These packages use the log transformation for arithmetic means and their ratios, the logit transformation for prevalences, and the hyperbolic arctangent or Fisher’s z transformation for differences between prevalences. Examples are presented for these packages.
Additional materials:
uk12_newson.pdf
In the robust statistics literature, a wide variety of models has been developed to cope with outliers in a rather large number of scenarios. Nevertheless, a recurrent problem for the empirical implementation of these estimators is that optimization algorithms generally do not perform well when dummy variables are present. What we propose in this paper is a simple solution to this involving the replacement of the subsampling step of the maximization procedures by a projection-based method. This allows us to propose robust estimators involving categorical variables, be they explanatory or dependent. Some Monte Carlo simulations are presented to illustrate the good behavior of the method.
Additional materials:
uk12_verardi_gassner_ugarte.pdf
We present the Stata package stgenreg for the parametric analysis of survival data. Any user-defined hazard or log hazard function can be specified, with the model estimated using maximum likelihood utilizing numerical quadrature. Standard parametric models (for example, the Weibull proportional hazards model and generalized gamma accelerated failure time model) can be fitted; however, the real advantage of the approach is the ability to fit parametric models not available in Stata or other software. Examples will include modeling the log hazard by using fractional polynomials and spline functions, fitting complex time-dependent effects, a generalized gamma model with proportional hazards, and generalized accelerated failure time models. An extensive range of prediction tools are also described.
Additional materials:
uk12_crowther_lambert.pdf
Following in the footsteps of the Stata user-written command ivtreatreg, recently proposed by the author (Cerulli, 2012), the paper presents a new Stata routine— contreatreg—for estimating a Dose Response Treatment Model under continuous treatment endogeneity and heterogeneous response to confounders. Compared with similar models—and in particular the one proposed by Hirano and Imbens (2004) implemented in Stata by Bia and Mattei (2008)—this model does not need the normality assumption; it is well suited when many individuals have a zero-level of treatment, and it accounts for treatment endogeneity by exploiting a two-step instrumental-variables (IV) estimation. The model considers two groups: 1) untreated, whose level of the treatment (or dose) is zero; and 2) treated, whose level of the treatment is greater than zero. Treated units' outcome y responds to treatment by a function h(t), assumed to have a flexible polynomial form. contreatreg estimates the model’s dose response function, which is shown to be equal to the average treatment effect, given the level of treatment t (that is, ATE(t)), along with other causal parameters of interest, such as the ATE, ATET, ATENT, and ATE(x; t). An application on real data will be provided along with the command’s ado and help files.
Additional materials:
uk12_cerulli.pdf
How to plot (and summarize) univariate distributions is a staple of introductory data analysis. Graphical (and numerical) assessment of marginal and conditional distributions remains important for much statistical modeling. Research problems can easily evoke needs for many comparisons, across groups, across variables, across models, and so forth. Over several centuries, many methods have been suggested, and their relative merits are a source of lively ongoing debate. I offer a selective but also detailed review of Stata functionality for univariate distributions. The presentation ranges from official Stata commands through various user-written commands, including some new programs, to suggestions on how to code your own graphics commands when other sources fail. I also discuss both continuous and discrete distributions. The trade-off between showing detail and allowing broad comparisons is an underlying theme.
Additional materials:
uk12_cox.ppt
Much interest has been focused on animated graphical displays of data in recent years, although this mostly involves some expertise with specialized software and programming. There is a lack of simple tools for data analysts to use to produce animations. In this presentation, I will show how movie files can be produced as stop-frame animations using Stata graphs as the building blocks. This approach is extremely flexible, and I will give some examples, including morphing from start to finish locations and the (ab)use of animation, color, and sound for emphasis. Some potential applications for teaching will be discussed. The principle of creating a sequence of transitional images through a loop, then calling the freeware, open-source ffmpeg software via winexec or shell will be explained with do-file examples. For repeated applications, the whole process can be contained within an ado-file, which raises the possibility of interactive websites with Stata, producing bespoke animations.
Additional materials:
uk12_grant.pptx
Visualizing the true effect of a predictor over a range of values can be difficult for models that are not parameterized in their natural metric, such as for logistic or (even more so) probit models. Interaction terms in such models cause even more fogginess. In this talk, I show how both the margins and the marginsplot commands can make for much clearer explanations of effects for both nonstatisticians and statisticians alike.
Additional materials:
uk12_rising.pdf
Propensity score matching has become a popular empirical method because of its capability of reducing the dimensionality of finding comparable units to conditioning on a scalar quantity. The validity of this approach relies on the balancing property of the propensity score. In practice, this is verified by using statistical tests along with subclassification. Within Stata, this is implemented by the program pscore provided by Becker and Ichino (2002). However, pscore is not constructive regarding the correct specification of the propensity score model, nor does it facilitate the actual requirement of covariate balance. The command pscore2 overcomes these drawbacks. It determines a set of intervals on the respective scalar-dimensional support of the propensity score with respect to the criterion that within each interval statistical similarity of covariates for treated and control observations cannot be rejected for a user-specified probability of a type-I error. Therefore, pscore2 implements a grid-search algorithm that updates the testing interval until convergence to the largest subinterval where covariate balance holds is achieved. The provided options allow for testing higher-order equivalence of each of the marginal covariate distributions for treated and controls. Furthermore, pscore2 automatically distinguishes between continuous and binary regressors and can handle nonvarying covariates.
References
Becker, S.O. and A. Ichino. 2002. Estimation of average treatment effects
based on propensity scores.
Stata Journal 2: 358–377.
Additional materials:
uk12_dorn.pdf
This presentation shows a somewhat complex automatization scheme in Stata that was developed during preparation of two papers using firm-level data and applying the propensity score matching techniques to distill the direct effects of the presence of foreign investors on various indicators from selection effects. The problem involved running multiple propensity score matching estimation procedures on different group of firms and on different efficiency measures. The solution involves 1) multiple nested loops to provide standardized output for several combinations of measures and groups; 2) correction of the standard PSM procedures to provide all required standard errors in the “returns”; and 3) use of postfiles to create user-friendly results sets that permit both reporting tables and generating publishable figures. The presentation also discusses alternative approaches that may be used to tackle similar problems.
Additional materials:
uk12_hagemejer_tyrowicz.ppt
Most of the microeconometrics studies are being based on the causal inference analysis. diff provides to the researcher an easy-to-use tool to perform the difference-in-differences estimation from a two-period panel dataset designed for an impact evaluation. It combines the conditional independence of the outcome and the treatment given unobservable characteristics that do not vary over time with the use of observable covariates. diff is endowed with four estimands: the single diff-in-diff; diff-in-diff accounting for covariates; the kernel propensity score diff-in-diff, which allows the selection of the bandwidth, the use of probit or logit, the provision of the propensity score, and the estimation on the common support; and the quantile diff-in-diff at the specified quantile, which is also available for continuous outcomes and it is combinable with the kernel option. Finally, option test performs the balancing test of covariates between treatment and comparison groups in the base-line period, generating a simple table based on Stata’s ttest.
Additional materials:
uk12_villa.pdf
In the presence of competing risks, calculation of cumulative incidence should provide a more realistic assessment of the probabilities of the event of interest conditional on covariates than provided by either the Kaplan–Meier failure probabilities or the event probabilities predicted directly from the Cox regression model. Enzo Coviello has previously provided user-written Stata programs that calculate either crude cumulative incidence estimates over time (stcompet) or cumulative incidence estimates over time adjusted to some user-specified values of covariates (stcompadj), which are useful for making between-group comparisons but have limitations for evaluating the individual risk predictions.
I will describe the motivation behind a new postestimation command (predcumi) that facilitates the calculation and visualization of cumulative incidence estimates after Cox regression models, calculated based on each individual’s covariate patterns or optionally with flexible adjustment of covariates to user-specified values or means or percentiles of the covariate distribution. The most recently fitted Cox model is assumed to be for the event of interest, and given the user’s specification of the competing event, the cumulative incidence calculations are based on cause-specific hazards estimated from Cox regressions. Examples will be provided and comparisons made with the previous user-written programs and Stata’s official implementation of competing risks models based on the Fine and Gray model formulation (stcrreg).
Additional materials:
uk12_kaptoage.ppt
We introduce a new integrate() function for Mata that evaluates single-dimensional integrals. This function uses three different Gaussian quadrature algorithms: Gauss–Hermite and Gauss–Laguerre for indefinite integrals; and Gauss–Legendre for definite integrals. The algorithms were implemented using the methods of Golub and Welsch (1968). The user can specify any integrand by defining a new function in the Mata language. The integrand function is allowed to have two arguments: the first is the variable of integration, and the second is a real scalar. Thus the integrate() function can be used in combination with optimise() to solve for the value of x in the following expression:
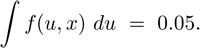
Such calculations are used in the sample size re-estimation methodology introduced by Li, Shih, and Xie (2002). We apply these methods to a clinical trial where a single interim analysis is carried out, and the analysis is used to reevaluate the sample size.
References
Golub, G.H. and J. H. Welsch. 1969. Calculation of Gauss quadrature rules.
Mathematics of Computation 23: 221–230.
Li, G., W. Shih, and T. Xie. 2002. A sample size adjustment procedure for clinical trials based on conditional power. Biostatistics 3: 277–287.
Additional materials:
uk12_mander_bowden.pdf
I present a new Stata command, simsam, that uses simulation to determine the sample size required to achieve given power for any method of analysis under any probability model that can be programmed in Stata (simsam assumes that code for generating a single dataset and analyzing it can be found in a separate program). Thus simsam extends Stata’s sampsi command. It is straightforward to estimate the power of a statistical analysis for a given sample size by simulation: you simply run the analysis repeatedly on simulated data and see how often the result is statistically significant. Determining the sample size that achieves given power is slightly harder, requiring power to be assessed at different sample sizes in order to find the one at which the target power is attained. simsam uses a novel iterative algorithm that is more efficient than stepping consecutively through every possible sample size. The user specifies the precision of the final estimate of power, but initially the algorithm uses less precision in order to make more rapid progress. The algorithm aims for the smallest sample size (or the smallest multiple of 5, or 10, or other user-specified increment) such that the power, estimated to within the specified precision, exceeds the target power. The power is reported with a 99% confidence interval, and the final sample size obtained is reliable in the sense that if the simsam command is repeated (by the same user or by a reviewer checking the calculation), it will, nearly every time, give a sample size no more than one increment away.
Additional materials:
uk12_hooper.pdf
I report briefly—and without giving away any Stata (or state) secrets—on my experiences as an intern at StataCorp earlier in 2012.
Additional materials:
uk12_crowther.pdf
In an era in which doctors and patients aspire to personalized medicine and more sophisticated risk estimation, detecting and modeling interactions between covariates or between covariates and treatment is increasingly important. In observational studies (for example, in epidemiology), interactions are known as effect modifiers; their presence can substantially change the understanding of how a risk factor impacts the outcome. However, modeling interactions in an appropriate and interpretable way is not straightforward.
In our talk, we consider two related topics. The first topic is modeling interactions in observational studies that involve at least one continuous covariate, an area that practitioners apparently find difficult. We introduce a new Stata program, mfpigen, for detecting and modeling such interactions using fractional polynomials, adjusting for confounders if necessary. The second topic is modeling interactions between treatment and continuous covariates in randomized controlled trials. We outline a Stata program, mfpi, designed for this purpose. Key themes of our talk are the vital role played by graphical displays of interactions and the importance of applying simple plausibility checks.
Additional materials:
uk12_royston_sauerbrei.pdf
Decomposition of the goodness of fit to (groups of) regressor variables can be a useful diagnostic tool to quickly assess “relative importance”. Owen and Shapley values, two closely related solutional concepts in cooperative game theory, provide unique solutions to the decomposition exercise on the basis of a sound set of assumptions. At this stage, the new command rego implements decomposition of R-squared in OLS regression, based on the covariance matrix of the data for fast computation in the Mata environment. It also allows for bootstrapping the outcomes. Inclusion of other measures of fit and classes of models is planned for future extensions.
Additional materials:
uk12_sunder.pdf
This presentation shows and applies a new user-written Stata command, enhancedeba, that facilitates the extreme bounds analysis (EBA) methodologies proposed by Leamer (1983, 1985) and Sala-i-Martin (1997). This command is useful for robustness checks and determining whether relationships between variables are strong. Many works have used the EBA methodology first presented in Leamer (1983, 1985), for example, Levine and Renelt (1992). Sala-i-Martin (1997) modified Leamer’s approach, and his approach can be found even more frequently in many empirical studies. However, to our knowledge, no program has been developed that can efficiently execute any type of extreme bounds analysis. Although Gregorio Impavido wrote a program in 1998 that uses Leamer’s EBA approach (simply called eba), no program has been developed for the use of Sala-i-Martin’s method. Furthermore, while being useful for simple regression tasks, Impavido’s program is limited in scope. The new program, enhancedeba, presented here seeks to enhance the currently available method. It can be used for any type of cross-sectional or panel regression, can do any number of variable combinations, and can be used for both the Leamer method and the Sala-i-Martin method.
Additional materials:
uk12_hadamovsky.pdf
In a 2012 article in the Journal of Business & Economic Statistics, Arthur Lewbel presents the theory of allowing the identification and estimation of “mismeasured and endogenous regressor models” by exploiting heteroskedasticity. These models include linear regression models customarily estimated with instrumental variables (IV) or IV-GMM techniques. Lewbel’s method, under suitable conditions, can provide instruments where no conventional instruments are available or augment standard instruments to enable tests of overidentification in the context of an exactly identified model. In this talk, I discuss the rationale for Lewbel’s methodology and illustrate its implementation in a variant of Baum, Schaffer, and Stillman’s ivreg2 routine, ivreg2h.
Additional materials:
uk12_baum_lewbel_schaffer_talavera.pdf
Discrete choice demand models are popular in applied analysis and can be estimated using market-level data on product shares and characteristics. The random parameters logit model is an extension to the traditional specification and can accommodate heterogeneity in consumer preferences and rich patterns of substitution over a large number of products. The purpose of this presentation is to set out a Stata program that estimates the parameters of this model by using the algorithm proposed by Berry, Levinsohn, and Pakes (1995) and that can also address the potential issues of price endogeneity. The estimator is coded in Mata and involves an inner-loop contraction mapping to invert the market shares, followed by an outer loop search over the parameters that minimizes a GMM objective function. The estimator allows the user to specify the variables that have random parameters and contains an additional option to generate a matrix of own and cross-price elasticities of demand.
References
Berry, S., J. Levinsohn, and A. Pakes. 1995. Automobile
prices in market equilibrium. Econometrica 63: 841–890.
Additional materials:
uk12_vincent.pdf
Nicholas J. Cox, Durham UniversityPatrick Royston, MRC Clinical Trials Unit
Timberlake Consultants, the official distributor of Stata in the United Kingdom, Brazil, Ireland, Poland, Portugal, and Spain.





