
1 item has been added to your cart.
We call them ERMs—extended regression models. There are four new commands that fit
The syntax of ERMs is a command, such as eregress, followed by the main equation and then followed by one or more of the options endogenous(), select(), and entreat() or extreat(). The options may be specified in any combination. For instance,
Linear regression of y on x1 and x2
. eregress y x1 x2
Make covariate x2 endogenous
. eregress y x1 , endogenous( x2 = x3 x4)
Add sample selection
. eregress y x1 , endogenous( x2 = x3 x4)
select(selected = x2 x6)
Add exogenous treatment & drop sample selection
. eregress y x1 , endogenous( x2 = x3 x4)
extreat(treated)
Replace exogenous with endogenous treatment
. eregress y x1 , endogenous( x2 = x3 x4)
entreat( treated = x2 x3 x5)
Add sample selection
. eregress y x1 , endogenous( x2 = x3 x4)
entreat( treated = x2 x3 x5)
select(selected = x2 x6)
Look carefully, and you will notice that we specified endogenous covariates in both selection and treatment equations. That ERMs can fit such models is remarkable. ERMs have one syntax and four options. The endogenous() option can be repeated when necessary:
Make x2 and x3 endogenous
. eregress y x1, endogenous(x2 = x3 x4)
endogenous(x3 = x1 x5)
Endogenous variable x3 in this example appears in the equations for both y and x2. If x3 was not to appear in the main equation, we would have typed
Remove x3 from the main equation
. eregress y x1, endogenous(x2 = x3 x4)
endogenous(x3 = x1 x5, nomain)
Even when we specify nomain, we can include the variables in the main equation as long as we do so explicitly:
. eregress y x1 x2 x3, endogenous(x2 = x3 x4, nomain)
endogenous(x3 = x1 x5, nomain)
The same syntax that works with eregress to fit linear regression models also works with eintreg to fit interval regression models, eprobit to fit probit models, and eoprobit to fit ordered probit models. For instance,
y is binary, model is probit
. eprobit y x1, endogenous(x2 = x3 x4)
endogenous(x3 = x1 x5, nomain)
There is only one more thing to know. Endogenous equations can themselves be probit or ordered probit. In the following model, endogenous covariate x3 is binary, and it is modeled using probit:
x3 is now a binary endogenous covariate
. eprobit y x1, endogenous(x2 = x3 x4)
endogenous(x3 = x1 x5, nomain probit)
We are going to fit the following model:
. eregress bmi sex steps , endog( steps = sex distance, nomain)
select(selected = sex steps education)
We will build up to fitting the model by relating the fictional story behind it, but first, notice that variable steps is endogenous and appears in both the main equation and the selection equation. We will have to account for that endogeneity if we hope to draw a causal inference about the effect of walking on body mass index.
. eregress bmi sex steps , endog( steps = sex distance, nomain)
select(selected = sex steps education)
Can ERMs really fit such models? Yes. We ran the model on simulated data and verified that the coefficients we are about to show you match the true parameters. Can other commands of Stata fit the same models as ERMs? Sometimes. There is no other Stata command that will fit a linear model with selection and with an endogenous covariate, but if variable steps were not endogenous, we could fit the model using Stata's heckman command. Nonetheless, ERMs are easier to use. And ERMs provide a richer set of model-interpretation features. Regardless, the important feature of ERMs is that they will fit a wider range of models, like the one we are about to fit:
. eregress bmi sex steps , endog( steps = sex distance, nomain)
select(selected = sex steps education)
The story behind this model concerns a (fictional) national study on the benefits of walking. This study is intended to measure those benefits in terms of the effects of steps walked per day (steps) on body-mass index (bmi).
A random sample was drawn and people were recruited to join the experiment. Some declined. We are going to ignore any bias in that. If they agreed, however, they were weighed, their height measured, their educational level recorded, and they were given a pedometer to be returned by prepaid post after six weeks. Some never returned it.
Our statistical concern is that those who did not return the pedometer might be systematically different from those who did. Perhaps they are less likely to exercise. Perhaps their bmi is higher than average. Remember that our goal is to measure the relationship between bmi and steps for the entire population.
Our other statistical concern has to do with unmeasured healthiness. People who walk more may be engaging in other activities that improve their health. We are worried that we have unobserved confounders. Said differently, we are worried that the error in bmi is correlated with the number of steps walked and thus bmi is endogenous.
We fit the model. Here are the results:
. eregress bmi sex steps , endog( steps = sex distance, nomain)
select(selected = sex steps education)
Iteration 0: log likelihood = -1422.7302
Iteration 1: log likelihood = -1420.2741
Iteration 2: log likelihood = -1419.9652
Iteration 3: log likelihood = -1419.9611
Iteration 4: log likelihood = -1419.9611
Extended linear regression Number of obs = 500
Selected = 302
Nonselected = 198
Wald chi2(2) = 640.17
Log likelihood = -1419.9611 Prob > chi2 = 0.0000
| Coef. Std. Err. z P>|z| [95% Conf. Interval] | ||
| bmi | ||
| sex | -1.080003 .3218772 -3.36 0.001 -1.710871 -.4491354 | |
| steps | -2.225672 .0891093 -24.98 0.000 -2.400323 -2.051021 | |
| _cons | 35.68498 .5815979 61.36 0.000 34.54507 36.82489 | |
| selected | ||
| sex | .8330193 .2647175 3.15 0.002 .3141825 1.351856 | |
| steps | .2694679 .0886263 3.04 0.002 .0957635 .4431723 | |
| education | 1.053498 .1027103 10.26 0.000 .8521891 1.254806 | |
| _cons | -16.63009 1.963632 -8.47 0.000 -20.47873 -12.78144 | |
| steps | ||
| sex | .3393479 .1044252 3.25 0.001 .1346783 .5440176 | |
| distance | -.985911 .0240427 -41.01 0.000 -1.033034 -.9387881 | |
| _cons | 9.035609 .0711241 127.04 0.000 8.896208 9.17501 | |
| var(e.bmi) | 7.916253 .7247563 6.615911 9.472174 | |
| var(e.steps) | .8907777 .0563377 .7869273 1.008333 | |
| corr(e.sel~d, | ||
| e.bmi) | .6676526 .0960975 6.95 0.000 .4355011 .8165333 | |
| corr(e.steps, | ||
| e.bmi) | .600721 .0400543 15.00 0.000 .5164193 .6734909 | |
| corr(e.steps, | ||
| e.selected) | .2030564 .123501 1.64 0.100 -.0465152 .4287674 | |
The parameter estimates are presented in five parts.
The first part reports the bmi equation.
The second part reports the selected equation.
The third part reports the steps equation.
The fourth part reports the error variances.
The fifth part reports the correlations between errors.
Let's start with the last part.
We worried that the errors in steps and bmi would be positively correlated, both being affected by unobserved healthiness. The output reports that the errors are indeed correlated. The estimated corr(e.steps, e.bmi) is 0.6, and it is whoppingly significant.
We worried that the error in selected would be correlated with the error in bmi, and it is. The estimated corr(e.selected, e.bmi) is 0.67, and it is significant too.
Our concerns are justified by the data, and, because we specified options selected() and endogenous(), the results reported in the main equation are adjusted for them. The results reported for the bmi equation are just as if we fit the model using ordinary regression on randomly selected data that had none of these problems.
The coefficient in the bmi equation that most interests us is the coefficient on steps. It is -2.23, meaning that bmi is reduced by 2.23 for every 1,000 steps walked per day. This is not a small effect. The average bmi in our data is 23.
Was it important that we accounted for endogeneity and selection? To show you that it was, we ran three other models:
. eregress bmi sex steps . eregress bmi sex steps , endog( steps = sex distance, nomain) . eregress bmi sex steps , select(selected = sex steps education)
The coefficients on steps were different in each model and not a single 95 percent confidence included -2.3, the true value under which the data were simulated.
Treatment-effect models are popular these days, and for good reason. Much of what researchers do involves evaluations of the effects of drugs, treatments, or programs.
In social sciences, evaluations are usually performed on observational data, another word for naturally occurring data. Even when data are custom to the purpose, they are seldom from well-controlled experiments. People opt in or out voluntarily. Even those who volunteer may not honor their obligations.
Consider the plight of a fictional university wanting to evaluate its freshman program intended to increase students' probabilities of ultimate graduation. This is a classic treatment-effects problem. Some students were treated (took the program) and others were not. The university now wants to measure the effect of the program.
The program was voluntary, meaning that students who are highly motivated might be more likely to participate. If highly motivated students are more likely to graduate in any case and if we ignored this problem, then the program would appear to affect college graduation rates more than it really does.
To measure the effect of the program, we need to do everything possible to control for each student's original chances of success. The model we will fit is
. eprobit graduate income i.roommate,
entreat(program = i.campus income)
endogenous( hsgpa = income i.hscomp)
The main probit equation models graduation, a 0/1 variable. We model student graduation on parents' income, whether the student had a roommate who was also a student (i.roommate), and high school GPA (hsgpa).
Option entreat() handles the endogenous treatment assignment. We model students' choice of treatment on (1) whether their first-year residence was on campus (i.campus) and (2) their parents' income (income). Both variables, we believe, affect the probability of participation.
Finally, we think high school GPA is endogenous because we believe it is correlated with unobserved ability and motivation.
We fit the model, and the output looks something like this:
. eprobit graduate income i.roommate,
endogenous(hsgpa = income i.hscomp)
entreat(program = i.campus income)
Extended probit regression Number of obs = 7,127
Wald chi2(8) = 1122.83
Log likelihood = -7920.6341 Prob > chi2 = 0.0000
| Coef. Std. Err. z P>|z| [95% Conf. Interval] | ||
| graduate | ||
| (output omitted) | ||
| program | ||
| (output omitted) | ||
| hsgpa | ||
| (output omitted) | ||
| var | ||
| (output omitted) | ||
| corr | ||
| (output omitted) | ||
We will show you the omitted parts, but first realize that the output appears in the same groupings as it did in the previous example. Equations are reported first (we have three of them), then variances, and, finally, correlations.
The second equation—program—is the treatment choice model. We want to start there. Our treatment choice model was specified by the entreat() option:
. eprobit graduate income i.roommate,
entreat(program = i.campus income)
endogenous( hsgpa = income i.hscomp)
The output for the treatment equation is
| program | ||
| campus | .6629004 .0467013 14.19 0.000 .5713675 .7544334 | |
| income | -.0772836 .0050832 -15.20 0.000 -.0872465 -.0673207 | |
| _cons | -.3417554 .0509131 -6.71 0.000 -.4415433 -.2419675 | |
We find that living on campus and being from a lower-income family increases the chances of students participating in the program. The negative coefficient on income did not surprise us. Our interpretation is that motivated students from poorer families expected they would have more to gain from the program.
Is the error in the treatment equation positively correlated with the error in the graduation equation? That correlation—corr(e.program, e.graduate)—is in the last part of the output,
| corr(e.pro~m, | ||
| e.graduate) | .2610808 .1162916 2.25 0.025 .0226638 .4713994 | |
| corr(e.hsgpa, | ||
| e.graduate) | .2905934 .0633915 4.58 0.000 .162068 .4094238 | |
| corr(e.hsgpa, | ||
| e.program) | -.0024032 .015235 -0.16 0.875 -.0322522 .0274501 | |
corr(e.program, e.graduate) is 0.26 and significant at the 5-percent level, providing evidence that treatment choice was indeed endogenous.
The third equation—hsgpa—is the model for our endogenous covariate—high school GPA. Our endogenous covariate model was specified by the endogenous() option:
. eprobit graduate income i.roommate,
entreat(program = i.campus income)
endogenous( hsgpa = income i.hscomp)
The output for the endogenous covariate equation is
| hsgpa | ||
| income | .0429837 .000954 45.06 0.000 .0411139 .0448535 | |
| hscomp | ||
| moderate | -.1180259 .0066271 -17.81 0.000 -.1310148 -.105037 | |
| high | -.2064778 .0104663 -19.73 0.000 -.2269914 -.1859643 | |
| _cons | 2.711822 .0075609 358.66 0.000 2.697003 2.726641 | |
We find that parents' income is positively related to high school GPA. We also find that school competitiveness (hscomp) matters. Students from moderately competitive high schools have lower high school GPAs, and those from highly competitive schools have still lower GPAs. The more difficult the school, the lower the expected GPA.
Taking all the above into account, we now ask, How did participation affect graduation rates? That will be in the graduate equation. Our model is
. eprobit graduate income i.roommate,
entreat(program = i.campus income)
endogenous( hsgpa = income i.hscomp)
and the output is
| graduate | ||
| program# | ||
| c.income | ||
| 0 | .1777645 .0140365 12.66 0.000 .1502534 .2052756 | |
| 1 | .2184452 .0181589 12.03 0.000 .1828543 .2540361 | |
| roommate# | ||
| program | ||
| yes#0 | .4320001 .0477783 9.04 0.000 .3383564 .5256437 | |
| yes#1 | .3548558 .0546206 6.50 0.000 .2478015 .4619102 | |
| program# | ||
| c.hsgpa | ||
| 0 | 1.860516 .3152604 5.90 0.000 1.242617 2.478415 | |
| 1 | 1.542167 .3131915 4.92 0.000 .9283226 2.156011 | |
| program | ||
| 0 | -6.567493 .8892133 -7.39 0.000 -8.310319 -4.824667 | |
| 1 | -5.18857 .8443761 -6.14 0.000 -6.843517 -3.533623 | |
Look carefully, and you will discover that even though we specified a single probit equation,
. eprobit graduate income i.roommate hsgpa, ...
an interacted-with-choice model was fit, yielding one set of coefficients for program==0 and another for program==1:
| Probit probability model of graduation | ||
| Variable program==0 program==1 | ||
| c.income 0.1778 0.2184 | ||
| i.roommate 0.4320 0.3546 | ||
| c.hsgpa 1.8605 1.5422 | ||
| intercept -6.5675 -5.1889 | ||
The graduation model was interacted with program because of the entreat(program = ...) option that we specified. When you specify the option, ERMs fit one model for each value of the treatment variable. This way of measuring treatment effects is more robust than when we allow only the intercept to vary across treatments. It is also more difficult to interpret.
Researchers who fit treatment-effect models are often interested in ATE and ATET. ATE is the average treatment effect—the difference between everyone being treated and everyone being untreated. In this case, that difference is the difference in graduation probabilities.
Postestimation command estat teffects reports the ATE:
. estat teffects Predictive margins Number of obs = 7,127 Model VCE : OIM
| Delta-method | ||
| Margin Std. Err. z P>|z| [95% Conf. Interval] | ||
| ATE | ||
| program | ||
| (1 vs 0) | .1687485 .0510067 3.31 0.001 .0687772 .2687198 | |
The ATE is a 0.1687 increase in the probability of graduation. That is a hefty increase.
ATE would be relevant if they could make the program required. With effects this large, they should want to think about how they could encourage students to enroll.
The fictional university is probably also interested in ATET—the average treatment effect among the treated. This is the average effect for students who self-selected into the program.
estat teffects will also report the ATET if we specify option atet:
. estat teffects, atet
Predictive margins Number of obs = 7,127
Subpop. no. obs = 3,043
Model VCE : OIM
| Delta-method | ||
| Margin Std. Err. z P>|z| [95% Conf. Interval] | ||
| ATE | ||
| program | ||
| (1 vs 0) | .1690133 .0523389 3.23 0.001 .0664311 .2715956 | |
The ATET is a 0.1690 increase in the probability of college graduation.
Are these effects constant? One of the reasons entreat() fits a fully interacted model by default is so that you can evaluate questions like that.
Let's explore the graduation probabilities as a function of parents' income and high school GPA. Our data contain incomegrp and hsgpagrp, which categorize those two variables.
Stata's margins command will handle problems like this. margins reports results in tables. When run after margins, marginsplot shows the same result as a graph. We could type
. margins, over(program incomegrp hsgpagrp) (output omitted) . marginsplot, plot(program) xlabels(0 4 8 12)
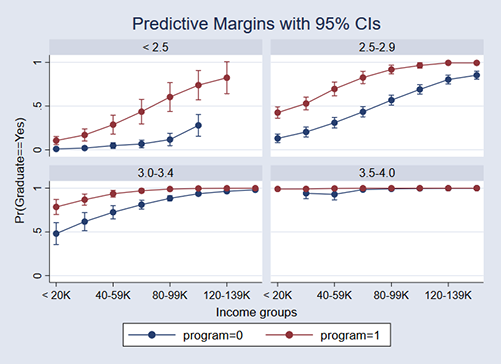
The graphs show the expected graduation rates for those who took the program (in red) and those who did not take the program (in blue). The four panels are GPA groups. The x axis of each graph is parents' income.
The program helps those with lower GPAs more and also those with moderately high GPAs from low-income families.
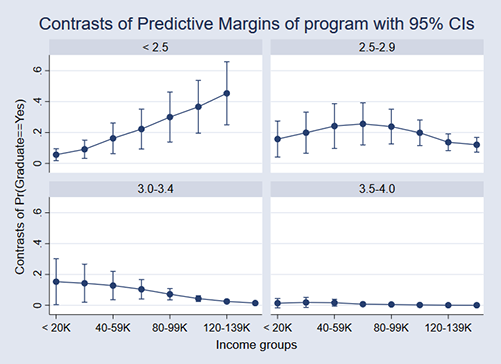
We like these graphs. Many researchers will want to graph the ATE. Here it is:
. margins r.program, over(incomegrp hsgpagrp) predict(fix(program)) (output omitted) . marginsplot, by(hsgpagrp) xlabels(0 4 8 12)
Learn more about Stata's extended regression models features.
ERMs are documented in their own new 259-page manual. It covers syntax and usage in detail, a much deeper development of the concepts, the statistical formulation of ERMs, and much more. See the Stata Extended Regression Models Reference Manual.
The Stata Extended Regression Models Reference Manual also demonstrates ERMs on ordered probit models and interval-measured outcomes models. It demonstrates other combinations of endogenous(), select(), extreat(), and entreat().
Here are links to examples from the manual that demonstrate specific models:
Linear regression with continuous endogenous covariate
Interval regression with continuous endogenous covariate
Interval regression with endogenous covariate and sample selection
Linear regression with binary endogenous covariate
Linear regression with exogenous treatment
Linear regression with endogenous treatment
Probit regression with continuous endogenous covariate
Probit regression with endogenous covariate and treatment
Probit regression with endogenous sample selection
Probit regression with endogenous treatment and sample selection
Probit regression with endogenous ordinal treatment
Ordered probit regression with endogenous treatment
Ordered probit regression with endogenous treatment and sample selection
Linear regression with endogenous covariate, sample selection, and endogenous treatment






