
1 item has been added to your cart.
Multilevel models are regression models that incorporate group-specific effects. Groups may represent different levels of hierarchy such as hospitals, doctors nested within hospitals, and patients nested within doctors nested within hospitals. Group-specific effects are assumed to vary randomly across groups according to some a priori distribution, commonly a normal distribution. This assumption makes multilevel models natural candidates for Bayesian analysis. Bayesian multilevel models additionally assume that other model parameters such as regression coefficients and variance components—variances of group-specific effects—are also random.
Why use Bayesian multilevel models? In addition to standard reasons for Bayesian analysis, Bayesian multilevel modeling is often used when the number of groups is small or in the presence of many hierarchical levels. Bayesian information criteria such as deviance information criterion (DIC) are also popular for comparing multilevel models. When the comparison of groups is of main interest, Bayesian multilevel modeling can provide entire distributions of group-specific effects.
You can now fit Bayesian multilevel models in Stata and you can do this easily—just prefix your multilevel command with bayes:
. bayes: mixed y x1 x2 || id:
Of course, when we say "easily", we refer to the model specification and not the model formulation. Just like any other modeling task, Bayesian multilevel modeling requires careful consideration.
Continuous, censored, binary, ordinal, count, GLM, and survival outcomes are supported; see the full list of supported multilevel commands. All multilevel features such as multiple levels of hierarchy, nested and crossed random effects, random intercepts and coefficients, and random-effects covariance structures are available. All Bayesian features as provided by the [BAYES] bayesmh command are supported when you use the bayes prefix with multilevel commands; read about general features of the bayes prefix.

Now, let's look at several examples.
Consider data on math scores of pupils in the third and fifth years from different schools in Inner London (Mortimore et al. 1988). We want to investigate a school effect on math scores.
We can use Stata's mixed command to fit a two-level linear model of five-year math scores (math5) on three-year math scores (math3) with random intercepts for schools.
. mixed math5 math3 || school:
Mixed-effects ML regression Number of obs = 887
Group variable: school Number of groups = 48
Obs per group:
min = 5
avg = 18.5
max = 62
Wald chi2(1) = 347.92
Log likelihood = -2767.8923 Prob > chi2 = 0.0000
| math5 | Coef. Std. Err. z P>|z| [95% Conf. Interval] | |
| math3 | .6088066 .0326392 18.65 0.000 .5448349 .6727783 | |
| _cons | 30.36495 .3491544 86.97 0.000 29.68062 31.04928 | |
| Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval] | |
| school: Identity | ||
| var(_cons) | 4.026853 1.189895 2.256545 7.186004 | |
| var(Residual) | 28.12721 1.37289 25.5611 30.95094 | |
The likelihood-ratio test at the bottom and the estimate of the school variance component suggest statistically significant variability between schools in the math5 scores after adjusting for the math3 scores.
To fit the corresponding Bayesian model, you can simply prefix the above mixed command with bayes:.
. bayes: mixed math5 math3 || school:
But here, we will first use bayes's melabel option to obtain output similar to that of mixed for easier comparison of the results.
. bayes, melabel: mixed math5 math3 || school:
Bayesian multilevel regression MCMC iterations = 12,500
Metropolis-Hastings and Gibbs sampling Burn-in = 2,500
MCMC sample size = 10,000
Group variable: school Number of groups = 48
Obs per group:
min = 5
avg = 18.5
max = 62
Number of obs = 887
Acceptance rate = .8091
Efficiency: min = .03366
avg = .3331
Log marginal likelihood max = .6298
| Equal-tailed | ||
| Mean Std. Dev. MCSE Median [95% Cred. Interval] | ||
| math5 | ||
| math3 | .6087689 .0326552 .000436 .6087444 .5450837 .6729982 | |
| _cons | 30.39202 .3597873 .01961 30.38687 29.67802 31.10252 | |
| school | ||
| var(_cons) | 4.272626 1.299061 .039697 4.122282 2.247659 7.220809 | |
| var(Residual) | 28.23014 1.37812 .017365 28.18347 25.63394 31.04375 | |
| Note: Default priors are used for some model parameters. | ||
The reported estimates of posterior means and posterior standard deviations for model parameters are similar to the corresponding maximum-likelihood estimates and standard errors reported by mixed.
Unlike mixed, which provided one estimate for each model parameter, bayes: mixed provided, for each parameter, a sample of 10,000 Markov chain Monte Carlo (MCMC) estimates from the simulated posterior distribution of the parameters. The reported posterior means and posterior distributions are the corresponding summaries of the marginal posterior distributions of the parameters.
Let's now see the output from bayes: mixed without the melabel option. The output is lengthy, so we will describe it in pieces.
. bayes
| Multilevel structure | ||
| school | ||
| {U0}: random intercepts | ||
| Model summary | ||
| Likelihood: | ||
| math5 ~ normal(xb_math5,{e.math5:sigma2}) | ||
| Priors: | ||
| {math5:math3 _cons} ~ normal(0,10000) (1) | ||
| {U0} ~ normal(0,{U0:sigma2}) (1) | ||
| {e.math5:sigma2} ~ igamma(.01,.01) | ||
| Hyperprior: | ||
| {U0:sigma2} ~ igamma(.01,.01) | ||
The header now includes additional information about the fitted Bayesian model. We can see, for example, that parameter {U0} represents random intercepts in the model, that regression coefficients {math5:math3} and {math5:_cons} are assigned default normal priors with zero means and variances of 10,000, and that the variance component for schools, {U0:sigma2}, is assigned the default inverse-gamma prior with 0.01 for both the shape and scale parameters.
In the output table, the results are the same, but the parameter labels are different.
| Equal-tailed | ||
| Mean Std. Dev. MCSE Median [95% Cred. Interval] | ||
| math5 | ||
| math3 | .6087689 .0326552 .000436 .6087444 .5450837 .6729982 | |
| _cons | 30.39202 .3597873 .01961 30.38687 29.67802 31.10252 | |
| school | ||
| U0:sigma2 | 4.272626 1.299061 .039697 4.122282 2.247659 7.220809 | |
| e.math5 | ||
| sigma2 | 28.23014 1.37812 .017365 28.18347 25.63394 31.04375 | |
| Note: Default priors are used for some model parameters. | ||
By default, bayes: mixed displays results using parameter names as you would use when referring to these parameters in bayes's options or during postestimation. For example, you would use {U0:sigma2} to refer to the variance component for schools and {e.math5:sigma2} to refer to the error variance.
There is still one part of the output missing—the estimates of random intercepts {U0}. In a Bayesian multilevel model, random effects are model parameters just like regression coefficients and variance components. bayes does not report them by default because there are often too many of them. But you can display them during or after estimation. Here we replay the estimation, adding the showreffects() option to display the estimates of the first 12 random intercepts.
. bayes, showreffects({U0[1/12]})
Bayesian multilevel regression MCMC iterations = 12,500
Metropolis-Hastings and Gibbs sampling Burn-in = 2,500
MCMC sample size = 10,000
Group variable: school Number of groups = 48
Obs per group:
min = 5
avg = 18.5
max = 62
Number of obs = 887
Acceptance rate = .8091
Efficiency: min = .03366
avg = .1749
Log marginal likelihood max = .6298
| Equal-tailed | ||
| Mean Std. Dev. MCSE Median [95% Cred. Interval] | ||
| math5 | ||
| math3 | .6087689 .0326552 .000436 .6087444 .5450837 .6729982 | |
| _cons | 30.39202 .3597873 .01961 30.38687 29.67802 31.10252 | |
| U0[school] | ||
| 1 | -2.685824 .9776969 .031227 -2.672364 -4.633162 -.7837494 | |
| 2 | .015465 1.290535 .03201 .0041493 -2.560203 2.556316 | |
| 3 | 1.049006 1.401383 .033731 1.021202 -1.534088 3.84523 | |
| 4 | -2.123055 .9921679 .028859 -2.144939 -4.069283 -.1507593 | |
| 5 | -.1504003 .9650027 .033881 -.1468966 -2.093015 1.721503 | |
| 6 | .5833945 1.192379 .032408 .5918357 -1.660335 3.049718 | |
| 7 | 1.490231 1.332917 .033846 1.481793 -1.095757 4.272903 | |
| 8 | .4198105 .9783772 .031891 .4579817 -1.496317 2.403908 | |
| 9 | -1.996105 1.02632 .035372 -2.001467 -4.037044 -.0296276 | |
| 10 | .6736806 1.249238 .031114 .660939 -1.70319 3.179273 | |
| 11 | -.5650109 .9926453 .031783 -.5839293 -2.646413 1.300388 | |
| 12 | -.3620733 1.090265 .033474 -.3203626 -2.550097 1.717532 | |
| school | ||
| U0:sigma2 | 4.272626 1.299061 .039697 4.122282 2.247659 7.220809 | |
| e.math5 | ||
| sigma2 | 28.23014 1.37812 .017365 28.18347 25.63394 31.04375 | |
| Note: Default priors are used for some model parameters. | ||
We could have used showreffects to display all 48.
To compare schools, we can plot posterior distributions (our prior normal distributions updated based on the observed data) of random intercepts. We plot histograms for the same first 12 random intercepts.
. bayesgraph histogram {U0[1/12]}, byparm
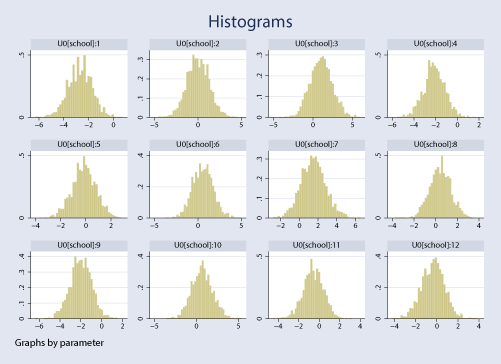
We save the MCMC results and store the estimation results from our Bayesian random-intercept model for later model comparison.
. bayes, saving(ri_mcmc) . estimates store ri
Our initial example used the default priors for model parameters. Just to show you how easy it is to specify custom priors, we specify a uniform on (-50,50) prior for the regression coefficients:
. bayes, prior({math5:}, uniform(-50,50)): mixed math5 math3 || school:
| Model summary | ||
| Likelihood: | ||
| math5 ~ normal(xb_math5,{e.math5:sigma2}) | ||
| Priors: | ||
| {math5:math3 _cons} ~ uniform(-50,50) (1) | ||
| {U0} ~ normal(0,{U0:sigma2}) (1) | ||
| {e.math5:sigma2} ~ igamma(.01,.01) | ||
| Hyperprior: | ||
| {U0:sigma2} ~ igamma(.01,.01) | ||
| Equal-tailed | ||
| Mean Std. Dev. MCSE Median [95% Cred. Interval] | ||
| math5 | ||
| math3 | .6094181 .0319517 .001432 .6085484 .5460873 .6732493 | |
| _cons | 30.36818 .3290651 .022103 30.38259 29.73806 31.0131 | |
| school | ||
| U0:sigma2 | 4.261459 1.282453 .040219 4.084322 2.238583 7.218895 | |
| e.math5 | ||
| sigma2 | 28.24094 1.374732 .016577 28.20275 25.68069 31.01401 | |
| Note: Default priors are used for some model parameters. | ||
{math5:} in the above is a shortcut for referring to all regression coefficients associated with the dependent variable math5: {math5:math3} and {math5:_cons}.
Similarly, we can use different priors for each regression coefficient, but we omit the output for brevity.
. bayes, prior({math5:_cons}, uniform(-50,50))
prior({math5:math3}, uniform(-5,5)): mixed math5 math3 || school:
Let's extend our simple random-intercept model to include a random coefficient.
Following mixed's specification, we include math3 in the random-effects equation for the school level. We also store our Bayesian estimation results for later comparison. This time, we save MCMC results during estimation.
. bayes, saving(rc_mcmc): mixed math5 math3 || school: math3 . estimates store rc
Here is abbreviated output from bayes: mixed, including a random coefficient for math3.
| Multilevel structure | ||
| school | ||
| {U0}: random intercepts | ||
| {U1}: random coefficients for math3 | ||
| Model summary | ||
| Likelihood: | ||
| math5 ~ normal(xb_math5,{e.math5:sigma2}) | ||
| Priors: | ||
| {math5:math3 _cons} ~ normal(0,10000) (1) | ||
| {U0} ~ normal(0,{U0:sigma2}) (1) | ||
| {U1} ~ normal(0,{U1:sigma2}) (1) | ||
| {e.math5:sigma2} ~ igamma(.01,.01) | ||
| Hyperprior: | ||
| {U0:sigma2} ~ igamma(.01,.01) | ||
| {U1:sigma2} ~ igamma(.01,.01) | ||
| Equal-tailed | ||
| Mean Std. Dev. MCSE Median [95% Cred. Interval] | ||
| math5 | ||
| math3 | .6143538 .0454835 .001655 .6137192 .5257402 .7036098 | |
| _cons | 30.38813 .3577296 .019669 30.3826 29.71581 31.10304 | |
| school | ||
| U0:sigma2 | 4.551927 1.368582 .041578 4.361247 2.420075 7.722063 | |
| U1:sigma2 | .0398006 .0194373 .001271 .0363514 .0131232 .0881936 | |
| e.math5 | ||
| sigma2 | 27.19758 1.354024 .021967 27.15869 24.71813 30.05862 | |
| Note: Default priors are used for some model parameters. | ||
mixed assumes independence between random intercepts and coefficients. bayes: mixed does too, to be consistent. We can relax this assumption by specifying an unstructured variance–covariance as follows. We save the MCMC results and store the estimation results from this model as well.
. bayes, saving(rcun_mcmc): mixed math5 math3 || school: math3, covariance(unstructured) . estimates store rcun
Here is abbreviated output from bayes: mixed specifying the unstructured covariance.
| Multilevel structure | ||
| school | ||
| {U0}: random intercepts | ||
| {U1}: random coefficients for math3 | ||
| Model summary | ||
| Likelihood: | ||
| math5 ~ normal(xb_math5,{e.math5:sigma2}) | ||
| Priors: | ||
| {math5:math3 _cons} ~ normal(0,10000) (1) | ||
| {U0}{U1} ~ mvnormal(2,{U:Sigma,m}) (1) | ||
| {e.math5:sigma2} ~ igamma(.01,.01) | ||
| Hyperprior: | ||
| {U:Sigma,m} ~ iwishart(2,3,I(2)) | ||
| Equal-tailed | ||
| Mean Std. Dev. MCSE Median [95% Cred. Interval] | ||
| math5 | ||
| math3 | .6234197 .0570746 .002699 .6228624 .5144913 .7365849 | |
| _cons | 30.34691 .3658515 .021356 30.34399 29.62991 31.07312 | |
| school | ||
| U:Sigma_1_1 | 4.527905 1.363492 .046275 4.345457 2.391319 7.765521 | |
| U:Sigma_2_1 | -.322247 .1510543 .004913 -.3055407 -.6683891 -.0679181 | |
| U:Sigma_2_2 | .0983104 .0280508 .000728 .0941222 .0556011 .1649121 | |
| e.math5 | ||
| sigma2 | 26.8091 1.34032 .018382 26.76549 24.27881 29.53601 | |
| Note: Default priors are used for some model parameters. | ||
We now use DIC to compare the three models: random-intercept model, random-coefficient model with independent covariance structure, and random-coefficient model with unstructured covariance structure.
. bayesstats ic ri rc rcun, diconly Deviance information criterion
| DIC | ||
| ri | 5514.514 | |
| rc | 5500.837 | |
| rcun | 5494.349 | |
DIC is the smallest for the random-coefficient model with an unstructured random-effects covariance, so this model is preferable.
To demonstrate that you can specify custom priors for not only scalar parameters but also matrices, we specify a custom inverse-Wishart prior for the random-effects covariance matrix {Sigma,m}, which is short for {Sigma,matrix}.
. matrix S = (5,-0.5\-0.5,1) . bayes, iwishartprior(10 S): mixed math5 math3 || school: math3, covariance(unstructured)
| Multilevel structure | ||
| school | ||
| {U0}: random intercepts | ||
| {U1}: random coefficients for math3 | ||
| Model summary | ||
| Likelihood: | ||
| math5 ~ normal(xb_math5,{e.math5:sigma2}) | ||
| Priors: | ||
| {math5:math3 _cons} ~ normal(0,10000) (1) | ||
| {U0}{U1} ~ mvnormal(2,{U:Sigma,m}) (1) | ||
| {e.math5:sigma2} ~ igamma(.01,.01) | ||
| Hyperprior: | ||
| {U:Sigma,m} ~ iwishart(2,10,S) | ||
| Equal-tailed | ||
| Mean Std. Dev. MCSE Median [95% Cred. Interval] | ||
| math5 | ||
| math3 | .6130199 .0537473 .00282 .613916 .5058735 .7180286 | |
| _cons | 30.3789 .3223274 .016546 30.3816 29.74903 31.02091 | |
| school | ||
| U:Sigma_1_1 | 3.482914 1.104742 .048864 3.344148 1.770735 6.0136 | |
| U:Sigma_2_1 | -.2712029 .1169666 .004214 -.2596221 -.5337747 -.0745626 | |
| U:Sigma_2_2 | .0775669 .0210763 .000651 .074876 .0443026 .1264642 | |
| e.math5 | ||
| sigma2 | 26.94206 1.342571 .022106 26.90405 24.4033 29.66083 | |
| Note: Default priors are used for some model parameters. | ||
The iwishartprior() option overrides the parameters of the default inverse-Wishart prior distributions used by bayes:. In our example, this prior is used for the covariance matrix with the default arguments of 3 degress of freedom and an identity scale matrix. In the above example, we instead used 10 degrees of freedom and the scale matrix S.
Consider survival data that record durations (in months) of employment of individuals from tstart to tend. Variable failure contains 1 when the end date corresponds to the end of employment, and 0 otherwise. A two-level model would account for the variability between individuals, who are identified by the id variable. To demonstrate a three-level model, let's also account for the variability between birth years of individuals, which may help explain some of between-individual variability.
Here is how we would proceed with the standard multilevel analysis for these data.
. stset tend, origin(tstart) failure(failure) . mestreg education njobs prestige i.female || birthyear: || id:, distribution(exponential)
We model the time to the end of employment as a function of the education level, the number of jobs held previously, the prestige of the current job, and gender.
In our Bayesian analysis, we will compare how well the two survival models, exponential and lognormal, fit these data.
First, we fit a Bayesian three-level exponential model by simply prefixing the above mestreg command.
. bayes: mestreg education njobs prestige i.female || birthyear: || id:, distribution(exponential)
The output is lengthy, so we describe it in parts.
The multilevel summary provides the names of parameters, {U0} and {UU0}, for random intercepts at the third and second levels of hierarchy, respectively. (Observations compose the first level.)
| Multilevel structure | ||
| birthyear | ||
| {U0}: random intercepts | ||
| birthyear>id | ||
| {UU0}: random intercepts | ||
The model summary describes the likelihood model and prior distributions used. For example, both variance components, {U0:sigma2} and {UU0:sigma2}, are assigned inverse-gamma prior distributions with scale and shape parameters of 0.01.
| Model summary | ||
| Likelihood: | ||
| _t ~ mestreg(xb__t) | ||
| Priors: | ||
| {_t:education njobs prestige 1.female _cons} ~ normal(0,10000) (1) | ||
| {U0} ~ normal(0,{U0:sigma2}) (1) | ||
| {UU0} ~ normal(0,{UU0:sigma2}) (1) | ||
| Hyperpriors: | ||
| {U0:sigma2} ~ igamma(.01,.01) | ||
| {UU0:sigma2} ~ igamma(.01,.01) | ||
The header information now includes a group summary for each hierarchical level.
Bayesian multilevel exponential PH regression MCMC iterations = 12,500
Random-walk Metropolis-Hastings sampling Burn-in = 2,500
MCMC sample size = 10,000
| No. of Observations per Group | ||
| Group Variable | Groups Minimum Average Maximum | |
| birthyear | 12 3 50.0 99 | |
| id | 201 1 3.0 9 | |
Just like mestreg, bayes: mestreg by default reports hazard ratios for the exponential survival model. You can use the nohr option to instead obtain coefficients. You can specify this option with bayes or mestreg during estimation or with bayes on replay.
. bayes, nohr
| Equal-tailed | ||
| Haz. Ratio Std. Dev. MCSE Median [95% Cred. Interval] | ||
| -t | ||
| education | 1.10707 .040724 .004527 1.107038 1.024029 1.188931 | |
| njobs | .7793024 .0354771 .002428 .7796324 .7114243 .8488112 | |
| prestige | .9707042 .0064944 .000412 .9707677 .9580977 .9835198 | |
| 1.female | 1.664841 .2483748 .026186 1.642104 1.229063 2.192569 | |
| _cons | .0137567 .0061351 .000673 .0126042 .0055763 .0287104 | |
| birthyear | ||
| U0:sigma2 | .1120806 .0969011 .006457 .0855433 .0092592 .382327 | |
| birthyear>id | ||
| UU0:sigma2 | .523587 .1229834 .010149 .5155754 .3040806 .8036657 | |
We save the MCMC results and store the estimation results from our Bayesian exponential survival model for later model comparison. We also specify the remargl option to compute the log marginal likelihood, which we explain below.
. bayes, remargl saving(streg_exp_mcmc) . estimates store streg_exp
Previously, we used bayes: mestreg to fit a Bayesian exponential survival model to employment duration data. If you look closely at the header output from bayes: mestreg,
Bayesian multilevel exponential PH regression MCMC iterations = 12,500
Random-walk Metropolis-Hastings sampling Burn-in = 2,500
MCMC sample size = 10,000
Number of obs = 600
Acceptance rate = .3045
Efficiency: min = .008093
avg = .01554
Log marginal likelihood max = .02482
you will notice that no value is reported for the log marginal likelihood (LML). This is intentional. As we mentioned earlier, Bayesian multilevel models treat random effects as parameters and thus may contain many model parameters. For models with many parameters or high-dimensional models, the computation of LML can be time consuming, and its accuracy may become unacceptably low. For these reasons, the bayes prefix does not compute the LML for multilevel models by default. You can specify the remargl option during estimation or on replay to compute it.
Here is a subset of the relevant output after typing
. bayes, remargl
Bayesian multilevel exponential PH regression MCMC iterations = 12,500
Random-walk Metropolis-Hastings sampling Burn-in = 2,500
MCMC sample size = 10,000
Number of obs = 600
Acceptance rate = .3045
Efficiency: min = .008093
avg = .01554
Log marginal likelihood = -2530.4131 max = .02482
Notice that the LML value is now reported in the header output.
Why do we need the value of LML? Some of the Bayesian summaries used for model comparison such as Bayes factors and model posterior probabilities are based on LML. In this example, we want to demonstrate the use of model posterior probabilities to compare Bayesian models, and so we needed to compute LML.
We now fit a Bayesian three-level lognormal model by specifying the corresponding distribution in the distribution() option. We also specify the remargl and saving() options during estimation this time.
. bayes, remargl saving(streg_lnorm_mcmc):
mestreg education njobs prestige i.female || birthyear: || id:,
distribution(lognormal)
Bayesian multilevel lognormal AFT regression MCMC iterations = 12,500
Random-walk Metropolis-Hastings sampling Burn-in = 2,500
MCMC sample size = 10,000
Number of obs = 600
Acceptance rate = .3714
Efficiency: min = .004755
avg = .01522
Log marginal likelihood = -2496.4991 max = .04602
| Equal-tailed | ||
| Mean Std. Dev. MCSE Median [95% Cred. Interval] | ||
| -t | ||
| education | -.0951555 .0314752 .002934 -.0947659 -.1563553 -.0348788 | |
| njobs | .1733276 .0423128 .004265 .1745013 .0871177 .2545806 | |
| prestige | .0272722 .0056387 .000263 .0272781 .0160048 .0384117 | |
| 1.female | -.3406851 .1323801 .018735 -.3383823 -.5965842 -.0912631 | |
| _cons | 3.822971 .4130557 .052204 3.817862 3.027644 4.635152 | |
| lnsigma | .0723268 .0419609 .002715 .0722478 -.0100963 .1569296 | |
| birthyear | ||
| U0:sigma2 | .1669752 .1566106 .013008 .120028 .0252243 .6019641 | |
| birthyear>id | ||
| UU0:sigma2 | .3061048 .1067159 .015475 .2919266 .1357847 .5485671 | |
| Note: Default priors are used for some model parameters. | ||
We now compare models using model posterior probabilities.
. bayestest model streg_exp streg_lnorm Bayesian model tests
| log(ML) P(M) P(M|y) | ||
| streg_exp | -2.53e+03 0.5000 0.0000 | |
| streg_lnorm | -2.50e+03 0.5000 1.0000 | |
The posterior probability for the lognormal model is essentially 1, so it is preferrable to the exponential model for these data.
In example 5 of [ME] melogit, we fit a crossed-effects model to the data from a study measuring students' attainment scores in primary and secondary schools from Fife, Scotland. The binary outcome of interest is whether the score is greater than 6. The model includes sex as the covariate and the effects of primary and secondary schools as crossed random effects.
. melogit attain_gt_6 sex || _all:R.sid || pid:
We fit the corresponding Bayesian crossed-effects model by simply prefixing the above melogit command with bayes:
. bayes: melogit attain_gt_6 sex || _all: R.sid || pid:
The output is lengthy, so as before, we describe it in parts.
| Multilevel structure | ||
| sid | ||
| {U0}: random intercepts | ||
| pid | ||
| {V0}: random intercepts | ||
We have two sets of random intercepts, {U0} and {V0}, at the secondary sid and primary pid levels, respectively.
| Model summary | ||
| Likelihood: | ||
| attain_gt_6 ~ melogit(xb_attain_gt_6) | ||
| Priors: | ||
| {attain_gt_6:sex _cons} ~ normal(0,10000) (1) | ||
| {U0} ~ normal(0,{U0:sigma2}) (1) | ||
| {V0} ~ normal(0,{V0:sigma2}) (1) | ||
| Hyperpriors: | ||
| {U0:sigma2} ~ igamma(.01,.01) | ||
| {V0:sigma2} ~ igamma(.01,.01) | ||
The likelihood model is a multilevel logistic model. The prior distributions are normal for regression coefficients and random intercepts and are inverse-gamma for the variance components.
| No. of Observations per Group | ||
| Group Variable | Groups Minimum Average Maximum | |
| _all | 1 3,435 3,435.0 3,435 | |
| pid | 148 1 23.2 72 | |
The header information includes the MCMC simulation summary as well as other details about the fitted Bayesian model.
| Equal-tailed | ||
| Mean Std. Dev. MCSE Median [95% Cred. Interval] | ||
| attain_gt_6 | ||
| sex | .2898934 .0731912 .004749 .2879629 .1568701 .4429235 | |
| _cons | -.6502969 .109456 .010693 -.6497501 -.8509903 -.4300285 | |
| sid | ||
| U0:sigma2 | .1484609 .0826556 .005049 .1336719 .0241995 .3532284 | |
| pid | ||
| V0:sigma2 | .4777177 .0954019 .004961 .4701 .3228973 .6864048 | |
| Note: Default priors are used for some model parameters. | ||
The results suggest that both primary and secondary schools contribute to the variation in whether the attainment score is greater than 6 after adjusting for sex in the model.
Instead of the estimates of coefficients, we can obtain the estimates of odds ratios.
. bayes, or
| Equal-tailed | ||
| Odds Ratio Std. Dev. MCSE Median [95% Cred. Interval] | ||
| attain_gt_6 | ||
| sex | 1.339886 .0988964 .00647 1.333708 1.169844 1.557253 | |
| _cons | .5250545 .0584524 .005902 .5221763 .4269919 .6504906 | |
| sid | ||
| U0:sigma2 | .1484609 .0826556 .005049 .1336719 .0241995 .3532284 | |
| pid | ||
| V0:sigma2 | .4777177 .0954019 .004961 .4701 .3228973 .6864048 | |
| Note: Estimates are transformed only in the first equation. | ||
| Note: _cons estimates baseline odds (conditional on zero random effects). | ||
| Note: Default priors are used for model parameters. | ||
We could have also specified the or option during estimation either with the bayes prefix
. bayes, or: melogit attain_gt_6 sex || _all: R.sid || pid:
or with melogit
. bayes: melogit attain_gt_6 sex || _all: R.sid || pid:, or
Mortimore, P., P. Sammons, L. Stoll, D. Lewis, and R. Ecob. 1988. School Matters: The Junior Years. Wells, Somerset, UK: Open Books.
Learn mode about the general features of the bayes prefix.
Learn more about Stata's Bayesian analysis features.
Read more about the bayes prefix and Bayesian analysis in the Stata Bayesian Analysis Reference Manual.






