
1 item has been added to your cart.
Finally, answers to real-world and real-research questions.
Prior to Stata 16, the nonlinearities and extra correlations in most choice models made it difficult to answer truly interesting questions. You could easily test whether a covariate was significant and positive but not measure its effect on the probability of a choice. Either you accepted answers to limited questions or you derived solutions to your specific questions and programmed them by hand.
That all changes with Stata 16. Even with complicated models such as multinomial probit or mixed logit, you can now get the answers to truly interesting questions. Your favorite restaurant introduces a new chicken entree? How does that affect demand for its other chicken entrees? Its beef entrees? Its fish entrees?
With Stata 16, answers to such questions, including tests and confidence intervals, are a simple command away.
We are consistently faced with making choices. For example:
With choice models, you can analyze relationships between such choices and variables that influence them.
Stata 16 introduces a new, unified suite of features for modeling choice data. The new commands are easy to use, and they provide the most powerful tools available for interpreting choice model results.
To get started with any choice model analysis, you first cmset your data, say,
. cmset id travelmode
You are now ready to summarize your choice data, fit models, and interpret the results.
Summarize:
With the new commands cmsummarize, cmchoiceset, cmtab, and cmsample, you can explore, summarize, and look for potential problems in your choice data.
Model:
Stata's commands for fitting choice models have been improved and renamed. You can use the new cm estimation commands to fit the following choice models:
| cmclogit | conditional logit (McFadden's choice) model |
| cmmixlogit | mixed logit model |
| cmxtmixlogit | panel-data mixed logit model |
| cmmprobit | multinomial probit model |
| cmroprobit | rank-ordered probit model |
| cmrologit | rank-ordered logit model |
cmxtmixlogit is another new feature of Stata 16. It fits mixed logit models for panel data, and we tell you all about it here.
Interpret:
Here's the most exciting part: margins now works after fitting any of these choice models. This means you can now easily interpret the results of your choice models. While the coefficients estimated in choice models are often almost uninterpretable, margins allows you to ask and answer very specific questions based on your results.
If you are modeling choice of transportation mode, you might ask questions such as
margins provides the answers to these questions and many others.
We have data recording individuals' choices of travel method between two cities.
Contains data from travel2.dta obs: 840 vars: 7 23 Jun 2019 09:37
| storage display value | ||
| variable name type format label variable label | ||
| chosen byte %8.0g travel mode chosen | ||
| income byte %8.0g household income | ||
| partysize byte %8.0g party size | ||
| id int %9.0g ID code | ||
| mode byte %8.0g travel travel mode | ||
| time float %9.0g travel time | ||
| income_cat byte %8.0g quart income quartiles | ||
| Sorted by: id | ||
To begin our analysis of these choice data, we tell Stata that the id variable identifies the cases (individuals) and the mode variable identifies the alternatives (modes of travel).
. cmset id mode
caseid variable: id
alternatives variable: mode
Before fitting a model, let's learn a little more about our data. cmtab shows us the proportion of individuals that chose each model of transportation. The option choice(chosen) says that the variable named chosen in our dataset records each individual's chosen travel mode.
. cmtab, choice(chosen) Tabulation of chosen alternatives (chosen = 1)
| travel mode | Freq. Percent Cum. | |
| air | 58 27.62 27.62 | |
| train | 63 30.00 57.62 | |
| bus | 30 14.29 71.90 | |
| car | 59 28.10 100.00 | |
| Total | 210 100.00 | |
Train transportation was most frequently chosen, but just slightly more often than air or car transportation. Only 14% of individuals took a bus.
We are interested in the effect of income on the chosen travel mode. Before we fit our model, let's look at the mean income for those who selected each travel mode.
. cmsummarize income, choice(chosen)
Statistics by chosen alternatives (chosen = 1)
income is constant within case
Summary for variables: income
by categories of: _chosen_alternative (chosen = 1)
| _chosen_alternative | mean | |
| air | 41.72414 | |
| train | 23.06349 | |
| bus | 29.7 | |
| car | 42.22034 | |
| Total | 34.54762 | |
Not surprisingly, average income is the highest among those who choose to travel by air and by car.
Now, let's fit a model and see what the results tell us about this relationship and others. To demonstrate, we fit a conditional logistic regression model using cmclogit, but the analysis that follows could be performed after fitting any other choice model.
We will include travel time, income, and the number of individuals traveling together (partysize) as covariates in our model. Travel time differs for each mode of transportation; it is called an alternative-specific variable. Income and party size do not vary across alternatives for an individual; they are known as case-specific variables and are listed in the casevars() option.
. cmclogit chosen time, casevars(income partysize)
Iteration 0: log likelihood = -249.36629
Iteration 1: log likelihood = -236.01608
Iteration 2: log likelihood = -235.65162
Iteration 3: log likelihood = -235.65065
Iteration 4: log likelihood = -235.65065
Conditional logit choice model Number of obs = 840
Case ID variable: id Number of cases = 210
Alternatives variable: mode Alts per case: min = 4
avg = 4.0
max = 4
Wald chi2(7) = 71.14
Log likelihood = -235.65065 Prob > chi2 = 0.0000
| chosen | Coef. Std. Err. z P>|z| [95% Conf. Interval] | |
| mode | ||
| time | -.0041641 .0007588 -5.49 0.000 -.0056512 -.002677 | |
| air | (base alternative) | |
| train | ||
| income | -.0613414 .0122637 -5.00 0.000 -.0853778 -.0373051 | |
| partysize | .4123606 .2406358 1.71 0.087 -.0592769 .883998 | |
| _cons | 3.39349 .6579166 5.16 0.000 2.103997 4.682982 | |
| bus | ||
| income | -.0363345 .0134318 -2.71 0.007 -.0626605 -.0100086 | |
| partysize | -.1370778 .3437092 -0.40 0.690 -.8107354 .5365798 | |
| _cons | 2.919314 .7658496 3.81 0.000 1.418276 4.420351 | |
| car | ||
| income | -.0096347 .0111377 -0.87 0.387 -.0314641 .0121947 | |
| partysize | .7350802 .2184636 3.36 0.001 .3068993 1.163261 | |
| _cons | .7471042 .6732971 1.11 0.267 -.5725338 2.066742 | |
What can we determine from these results? The coefficient on time is negative, so the probability of choosing any method of travel decreases as its travel time increases.
For the train alternative, the coefficient on income is negative. Because air travel is the base alternative, this negative coefficient tells us that as income increases, people are less likely to choose a train over an airplane. For the car alternative, the coefficient on partysize is positive. As party size increases, people are more likely to choose a car over an airplane.
But what about questions that we can't answer from this output? For instance, what happens to the probability of selecting car travel as income increases? This is where margins comes in.
Let's estimate the expected proportion of travelers who would choose car travel across income levels ranging from $30,000 to $70,000 per year.
. margins, at(income=(30(10)70)) outcome(car) Predictive margins Number of obs = 840 Model VCE : OIM Expression : Pr(mode|1 selected), predict() Outcome : car 1._at : income = 30 2._at : income = 40 3._at : income = 50 4._at : income = 60 5._at : income = 70
| Delta-method | ||
| Margin Std. Err. z P>|z| [95% Conf. Interval] | ||
| _at | ||
| 1 | .2717914 .0329811 8.24 0.000 .2071497 .3364331 | |
| 2 | .3169817 .0329227 9.63 0.000 .2524544 .3815091 | |
| 3 | .3522391 .0391994 8.99 0.000 .2754097 .4290684 | |
| 4 | .3760093 .050679 7.42 0.000 .2766802 .4753383 | |
| 5 | .3889296 .0655865 5.93 0.000 .2603825 .5174768 | |
In the first line, we see that at the $30,000 income level, 27% of travelers are expected to choose car travel. But at the $70,000 income level, 39% are expected to choose car travel.
If we simply type marginsplot, we can easily visualize the effect of income.
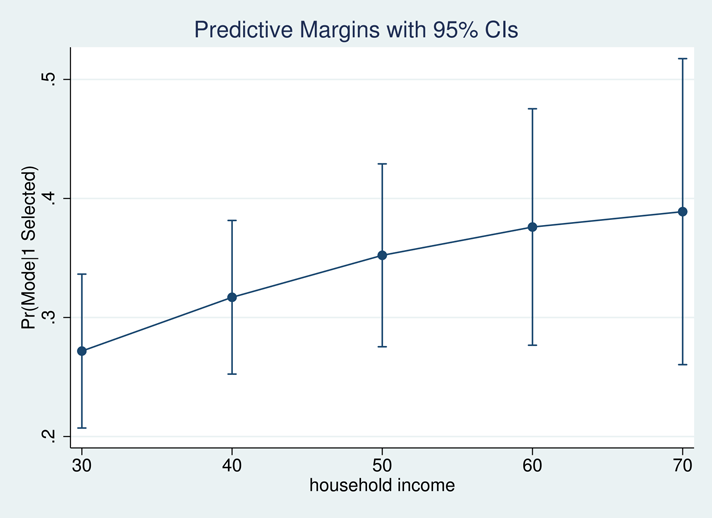
We see that the expected probability of choosing car transportation increases as income increases. But are these differences statistically significant?
We can again use margins to answer this question. Specifying the contrast() option, we can test for differences in the expected probabilities for each $10,000 increase in income. The atcontrast(ar) option requests reverse adjacent contrasts—comparisons with the previous income level.
. margins, at(income=(30(10)70)) outcome(car) contrast(atcontrast(ar) nowald effects) Contrasts of predictive margins Number of obs = 840 Model VCE : OIM Expression : Pr(mode|1 selected), predict() Outcome : car 1._at : income = 30 2._at : income = 40 3._at : income = 50 4._at : income = 60 5._at : income = 70
| Delta-method | ||
| Contrast Std. Err. z P>|z| [95% Conf. Interval] | ||
| _at | ||
| (2 vs 1) | .0451903 .016664 2.71 0.007 .0125296 .0778511 | |
| (3 vs 2) | .0352574 .017903 1.97 0.049 .0001681 .0703466 | |
| (4 vs 3) | .0237702 .0190387 1.25 0.212 -.013545 .0610854 | |
| (5 vs 4) | .0129204 .0200549 0.64 0.519 -.0263866 .0522273 | |
At a 5% significance level, the effect of a $10,000 increase in income is statistically significant only when going from $30,000 to $40,000 (2 vs 1) and from $40,000 to $50,000 (3 vs 2).
Above, we have results for car travel, but we can easily estimate similar effects for each other travel alternative. We simply change outcome(car) to outcome(train) or any of the other outcomes. Or we can remove the outcome() option altogether and get estimates for all outcomes. This is helpful if you want to compare effects of income across all modes of transportation. For instance, if we type
. margins, at(income=(30(10)70)) . marginsplot, noci
we see how the expected probability of selecting each transportation mode changes across income levels.
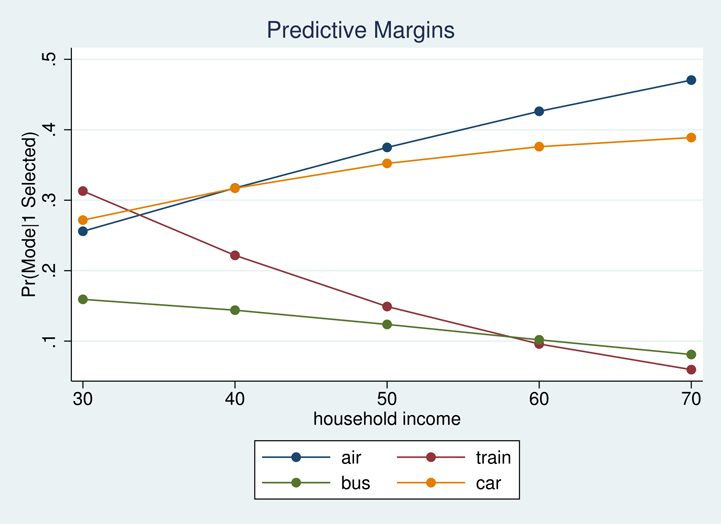
So far, we have focused on the effects of income. What about analyzing the effect of an alternative-specific variable like time? We can ask different questions for these variables. For instance, if wait times at airports increase by an hour, how do we expect this to affect the probability of selecting air travel? How does it affect the probability of selecting car travel? Train travel? Bus travel?
We find out by typing
. margins, at(time=generate(time)) at(time=generate(time+60)) alternative(air)
The first at() option requests expected probabilities without the additional travel time, and the second at() option requests expected probabilities with an additional 60 minutes added to air travel time.
| Delta-method | ||
| Margin Std. Err. z P>|z| [95% Conf. Interval | ||
| _outcome#_at | ||
| air#1 | .2761905 .0275268 10.03 0.000 .2222389 .330142 | |
| air#2 | .2379693 .0258772 9.20 0.000 .1872509 .2886878 | |
| train#1 | .3 .0284836 10.53 0.000 .2441731 .3558269 | |
| train#2 | .3134023 .0293577 10.68 0.000 .2558623 .3709424 | |
| bus#1 | .1428571 .0234186 6.10 0.000 .0969576 .1887567 | |
| bus#2 | .1514859 .024598 6.16 0.000 .1032747 .1996972 | |
| car#1 | .2809524 .028043 10.02 0.000 .2259891 .3359156 | |
| car#2 | .2971424 .0289281 10.27 0.000 .2404443 .3538405 | |
Not surprisingly, we see a decrease in the expected probability of traveling by air from 0.276 to 0.238. The expected probabilities of selecting any of the other travel modes increase slightly.
Again, we can use marginsplot to visualize the effect of this change in air travel time.
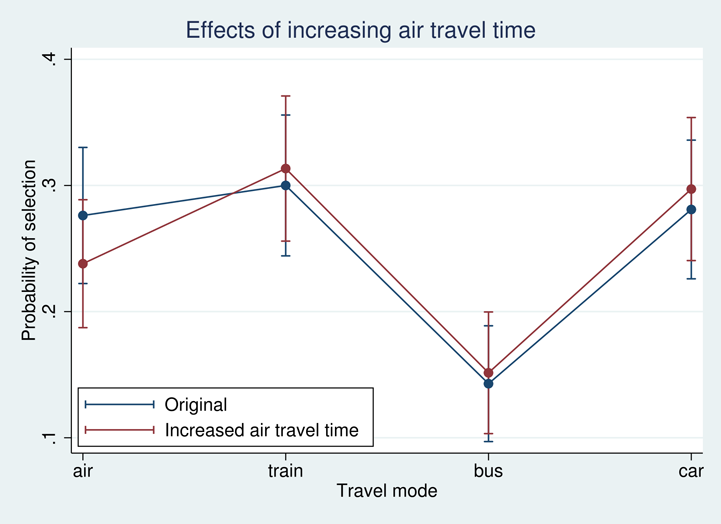
Here we have given you only a taste of the types of analyses you can now perform using margins.
For more about inference using margins, see [CM] Intro 1.
Learn more about Stata's choice model features.
Read more about Stata's commands for choice models in the Stata Choice Models Reference Manual.




