
1 item has been added to your cart.
Existing command menl has new features for fitting nonlinear mixed-effects models (NLMEMs) that may include lag, lead (forward), and difference operators. One important class of such models is the class of pharmacokinetic (PK) models and, specifically, multiple-dose PK models. menl's new features can also be used to fit other models, such as certain growth models and time-series nonlinear multilevel models.
Growth models based on difference equations are often used to model animal growth. For instance, Andrews (1982) used the so-called logistic-by-weight model to model the growth of small lizards. Wright et al. (2013) applied this model to study the length of brown anole lizards. The authors also extended the model to account for the between-lizard variation by including random effects.
Inspired by the above studies, we created our own fictional data on lengths of small lizards. In what follows, we will use menl to fit a random-effects logistic-by-weight model to these data.
First, let's take a quick look at the data. We list the observations for the first two lizards.
. list if id<=2, sepby(id)
| id time length | |
| 1. | 1 103 22.83874 |
| 2. | 1 208 29.38543 |
| 3. | 1 310 35.20067 |
| 4. | 1 411 39.46608 |
| 5. | 1 512 40.801 |
| 6. | 2 5 28.97618 |
| 7. | 2 212 38.83975 |
| 8. | 2 313 41.70709 |
Lizards were captured and their length measured. Then, they were marked and released. After that, the lizards were recaptured at different times, and their length was recorded again. Variable time contains the number of days since the beginning of the study, and length records the length (in mm) of lizards.
The interval version of the random-effects logistic-by-weight model can be defined as
$$ L_{ij} = \left\{ \frac{a^3 L_{i-1,j}^3} {L_{i-1,j}^3 +(a^3-L_{i-1,j}^3)\times e^{-r_jD_{i,j}}} \right\}^{(1/3)} +\epsilon_{ij} $$
where \(L_{ij}\) is the length of lizard \(j\) at time \(i\) and \(D_{ij}\) is the difference in days between measurements \(i-1\) and \(i\) for lizard \(j\). Model parameters are lizard-specific growth rate, \(r_j\), and asymptotic length, \(a\). Here \(\epsilon_{ij}\sim N(0,\sigma_\epsilon^2)\) and \(r_j=r_0+u_j\) and \(u_j\sim N(0,\sigma_r^2)\), where \(r_0\) is the mean growth rate, \(\sigma_r^2\) is the between-lizards variance, and \(\sigma_\epsilon^2\) is sampling error variance.
Let's fit the above model using menl. Our menl specification is as follows.
. menl length = ({a}^3*L.length^3/(L.length^3+({a}^3-L.length^3)*exp(-{r:}*D.time)))^(1/3),
define(r: U[id], xb)
tsorder(time)
stddeviations initial({a} 40)
We specify the above nonlinear model using menl's standard nonlinear specification with model parameters enclosed in curly braces, {}. New in the above specification are the uses of the lag operator L. (with variable length) and the difference operator D. (with variable time).
The define() option models the lizard-specific growth rate, \(r_j\), as a random effect, \(u_j\), plus a constant, \(r_0\). tsorder() specifies the time variable that will be used by the L. and D. operators to create the lagged and differenced versions of the variables. Variable id in the term U[id] identifies the grouping structure of our dataset. initial() specifies the initial value for the asymptotic length.
Let's now run menl.
. menl length = ({a}^3*L.length^3/(L.length^3+({a}^3-L.length^3)*exp(-{r:}*D.time)))^(1/3),
define(r: U[id], xb)
tsorder(time)
stddeviations initial({a} 40)
panel variable: id (unbalanced)
time variable: <time>, 1 to 5
delta: 1 unit
Alternating PNLS/LME algorithm:
Iteration 1: linearization log likelihood = -151.155891
Iteration 2: linearization log likelihood = -151.763053
Iteration 3: linearization log likelihood = -151.762528
Iteration 4: linearization log likelihood = -151.762566
Iteration 5: linearization log likelihood = -151.762565
Computing standard errors:
Mixed-effects ML nonlinear regression Number of obs = 145
Group variable: id Number of groups = 50
Obs per group:
min = 2
avg = 2.9
max = 4
Linearization log likelihood = -151.76257
r: U[id], xb
| length | Coef. Std. Err. z P>|z| [95% Conf. Interval] | |
| r | ||
| _cons | .0097474 .0001969 49.51 0.000 .0093615 .0101333 | |
| /a | 42.51087 .1592405 266.96 0.000 42.19876 42.82297 | |
| Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval] | |
| id: Identity | ||
| sd(U) | .0007285 .0001551 .0004799 .0011058 | |
| sd(Residual) | .6235789 .0425276 .5455571 .712759 | |
The estimated asymptotic length is 42.5 mm with a standard error of 0.16, and the mean growth rate is 0.0097 with a standard error of 0.0002. The between-lizards standard deviation for the growth rate is 0.0007 with a 95% CI of [0.0005, 0.0011], which suggests that there is variability in lizards' growth rates compared with their mean value.
Let's visualize the predicted growth rates for lizards. We can use predict to compute the predictions not only for the response but also for any parameter or function defined in define(). So we use predict to compute lizard-specific and mean growth rates.
. predict (rate = {r:})
. predict (mean_rate = {r:}), fixedonly
Next, we plot the predicted growth rates.
. twoway scatter rate id || line mean_rate id,
xtitle("Lizard identifier") ytitle("Predicted growth rate")
title("Predicted growth rates for lizards")
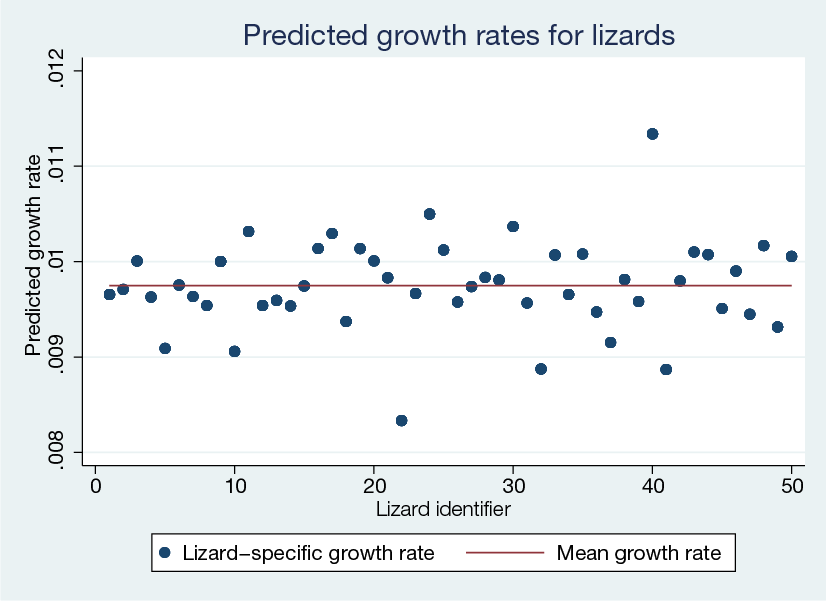
The growth rates of lizards vary around the mean value of 0.0097, with the largest value of 0.0113 for lizard 40 and the smallest value of 0.0083 for lizard 22.
PK models concern drug absorption, distribution, metabolism, and excretion. Single-dose and multiple-dose models are of special interest. Each comes in two flavors distinguished by how long it takes the drug to enter the body: orally or intravenously. menl can fit all those models.
Let's use menl to fit a multiple-dose model with intravenous administration. Consider a study of the neonatal PKs of phenobarbital (Grasela and Donn 1985). Each infant received one or more intravenous doses, dose (mg/kg). One to six blood serum phenobarbital concentration measurements, conc (mg/L), were obtained from each infant, subject. Other variables of interest are birthweight and a dichotomized Apgar score (fapgar), a measure of the physical condition.
A one-compartment open model with intravenous administration and first-order elimination was used to model the PKs of this phenobarbital study.
$$ {\mbox{conc}}_{ij} = \frac{{\mbox {dose}}_{ij}}{V_j} + E(\mbox{conc}_{i-1, j})\times\exp\left\{ \frac{Cl_j}{V_j}(\mbox{time}_{ij}-\mbox{time}_{i-1,j})\right\} + \epsilon_{ij} $$Model parameters are the clearance, \(Cl_j\) (L/h), and volume of distribution, \(V_j\) (L), for each infant \(j\). \(E(\mbox{conc}_{i-1, j})\) is the expected concentration at measurement time \(i-1\) for infant \(j\).
In addition, \(Cl_j\) and \(V_j\) are parameterized as follows,
\begin{equation}\label{Cl} CL_j = \beta_1\mbox{weight}_j\times \exp(u_{1j}) \end{equation} \begin{equation} \label{V} V_j = \beta_2\mbox{weight}_j\{1+\beta_3 \mbox{fapgar}_j\times \exp(u_{2j})\} \end{equation}
where \(u_{1j}\) and \(u_{2j}\) are two independent Gaussian random effects with zero means and the corresponding variances \(\sigma^2_{1}\) and \(\sigma^2_{2}\).
The menl specification is the following.
. menl conc = dose/{V:} + L.{conc:}*exp(-{Cl:}/{V:}*D.time),
define(Cl: {cl:weight}*weight*exp({U1[subject]}))
define( V: {v:weight}*weight*(1+{v:apgar}*1.fapgar)*exp({U2[subject]}))
tsoder(time) tsinit({conc:} = dose/{V:}) tsmissing
The explanation of the syntax follows.
We now fit the model.
. menl conc = dose/{V:} + L.{conc:}*exp(-{Cl:}/{V:}*D.time),
define(Cl: {cl:weight}*weight*exp({U1[subject]}))
define( V: {v:weight}*weight*(1+{v:apgar}*1.fapgar)*exp({U2[subject]}))
tsorder(time) tsinit({conc:} = dose/{V:}) tsmissing
panel variable: subject (unbalanced)
time variable: <time>, 1 to 20
delta: 1 unit
Obtaining starting values by EM:
Alternating PNLS/LME algorithm:
Iteration 1: linearization log likelihood = -432.588874
Iteration 2: linearization log likelihood = -436.355248
Iteration 3: linearization log likelihood = -436.367352
Iteration 4: linearization log likelihood = -436.36894
Iteration 5: linearization log likelihood = -436.368999
Iteration 6: linearization log likelihood = -436.36896
Computing standard errors:
Mixed-effects ML nonlinear regression Number of obs = 685
Nonmissing = 155
Missing = 530
| No. of Observations per Group | ||
| Path | Groups Minimum Average Maximum | |
| subject | 59 1 11.6 19 | |
| conc | 59 1 2.6 6 | |
| conc | Coef. Std. Err. z P>|z| [95% Conf. Interval] | |
| /cl | ||
| weight | .004705 .0002219 21.20 0.000 .0042701 .00514 | |
| /v | ||
| weight | .9657032 .0294438 32.80 0.000 .9079945 1.023412 | |
| apgar | .1749755 .0845767 2.07 0.039 .0092082 .3407429 | |
| Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval] | |
| subject: Independent | ||
| var(U1) | .0404098 .0187133 .0163044 .1001537 | |
| var(U2) | .030259 .0078857 .0181562 .0504295 | |
| var(Residual) | 7.469354 1.280411 5.337875 10.45196 | |
Heavier babies have a higher clearance and volume of distribution. There is a positive association between the volume of distribution and the Apgar score: healthier babies have a better ability to eliminate the drug.
After estimation, let's use predict to predict concentrations.
. predict yhat (option yhat assumed)
The default prediction is the predicted mean function, including the estimates of subject-specific random effects. So variable yhat contains observation-specific mean concentration for each infant.
Let's plot the predicted concentration against the observed one for, say, the first four infants.
. twoway (scatter yhat time) (scatter conc time) if subject<=4,
ytitle("Concentration (mg/L)") xtitle("Time (hr)")
by(subject, title("Infant-specific concentrations of phenobarbital"))
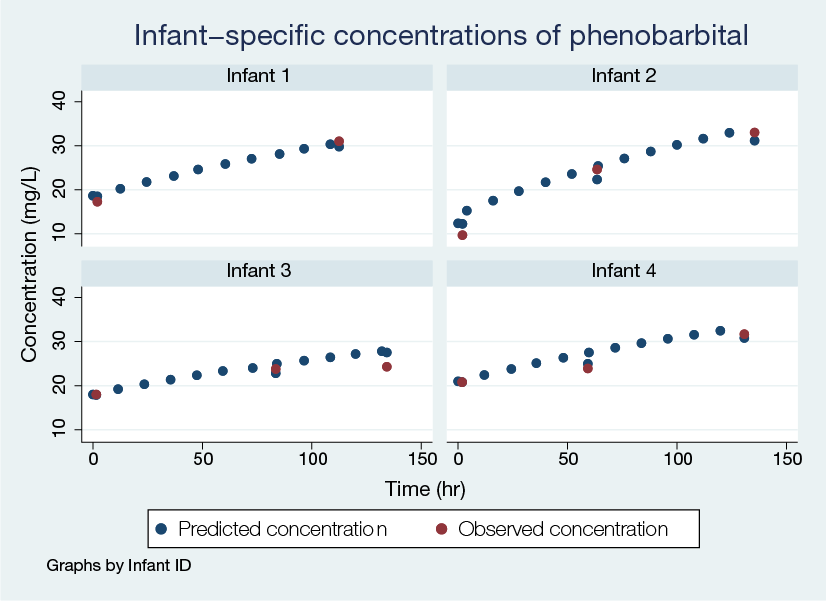
The model predicted the missing intermittent concentrations and provided the entire trajectory of the concentration for the observed measurement times.
In addition, menl provides two new within-group error structures: Toeplitz and banded. They can be specified within options rescovariance() and rescorrelation() as toeplitz # and banded #, respectively, where # defines the order of the error structures.
menl also provides new option lrtest, which reports a likelihood-ratio test comparing the nonlinear mixed-effects model with the model fit by ordinary nonlinear regression.
For more details about this example, see Example 17: Multiple-intravenous-doses model in [ME] menl. Also see Example 18: Multiple-oral-doses model in that same entry.
Andrews, R. 1982. Patterns of growth in reptiles. In Biology of the Reptilia, vol. 13, ed. C. Gans and F. H. Pough, 273–320. New York: Academic Press.
Grasela, T. H., Jr., and S. M. Donn. 1985. Neonatal population pharmacokinetics of phenobarbital derived from routine clinical data. Developmental Pharmacology and Therapeutics 8: 374–383.
Wright, A. N., J. Piovia-Scott, D. A. Spiller, G. Takimoto, L. H. Yang, and T. W. Schoener. 2013. Pulses of marine subsidies amplify reproductive potential of lizards by increasing individual growth rate. Oikos 122: 1496–1504
Read more about pharmacokinetic modeling and time-series operators in [ME] menl.
Learn more about Stata's multilevel mixed-effects models.





