
1 item has been added to your cart.

Survival-time outcomes measure durations such as time to death, length of hospital stay, time to recurrence of a particular type of cancer, or length of time living in a city. We can fit survival models to evaluate the effects of covariates on these survival times.
For example, we might be interested in high school students who are at risk of dropping out of school. We can model the number of months from the start of ninth grade until dropout as a function of grade point average, attendance, and eighth-grade achievement test scores. We can fit either a parametric or a semiparametric model with Stata's streg or stcox commands.
For more complex models, we can use gsem to model survival-time outcomes as part of a larger structural equation model. gsem fits multilevel structural equation models and structural equation models with binary, ordinal, count, and other types of outcomes. What does this mean for modeling survival-time outcomes? Let's consider some extensions to our model for time to dropout.
Suppose that at the beginning of ninth grade, each at-risk student in our sample answered a series of questions regarding the support each receives from parents, teachers, counselors, and peers. The responses to these questions measure the student's perceived level of support, a latent concept that we believe affects time to dropout. gsem allows us to include a latent variable as a predictor of time to dropout.
Perhaps we believe that time to dropout is also affected by unobserved characteristics of the school such as an administrator's abilities to identify early warning signs of dropout. With gsem, we can include school-level random effects in our model.
Say that we are also interested in modeling a count outcome, the number of times a student has been in trouble at school. We believe this outcome is also related to the student's perceived level of support. With gsem, we can simultaneously fit a Weibull model for time to dropout and a Poisson model for number of offenses at school, and the two models can be tied together through the student's perceived level of support. We can also include number of offenses as a predictor of time to dropout.
In other words, gsem allows us to extend parametric models for survival-time outcomes to include latent variables, to include multiple levels of random effects, and to include multiple outcomes.
Now, let's consider another type of survival-time outcome.
We want to analyze survival times of nursing home residents. We have censored data; thankfully, not all the residents have died yet.
We posit that survival times are determined by age, depression level, and overall health. Both depression and overall health are latent traits. We have four variables that measure aspects of depression and four variables that measure aspects of overall health. We fit a Weibull model for survival time along with the measurement models for depression and overall health.
We can create our model using Stata's SEM Builder:
;)
Or we can type the command
. gsem (surv_time <- age Depress Health,
family(weibull, fail(death)))
(Depress -> dep1 dep2 dep3 dep4)
(Health -> hlth1 hlth2 hlth3 hlth4),
variance(Depress@1 Health@1)
The results are
| Coef. Std. Err. z P>|z| [95% Conf. Interval] | ||
| surv_time <- | ||
| age | .1078273 .0120192 8.97 0.000 .0842701 .1313844 | |
| Depress | 1.2204 .1143472 10.67 0.000 .9962836 1.444516 | |
| Health | -1.782012 .1526019 -11.68 0.000 -2.081106 -1.482918 | |
| _cons | -6.949501 .8724378 -7.97 0.000 -8.659448 -5.239554 | |
| dep1 <- | ||
| Depress | 1.038601 .0409685 25.35 0.000 .9583046 1.118898 | |
| _cons | .091441 .0510287 1.79 0.073 -.0085734 .1914553 | |
| dep2 <- | ||
| Depress | .5079995 .0381469 13.32 0.000 .433233 .582766 | |
| _cons | .0439719 .039877 1.10 0.270 -.0341856 .1221295 | |
| dep3 <- | ||
| Depress | .7126734 .0370931 19.21 0.000 .6399723 .7853746 | |
| _cons | .0856129 .0421749 2.03 0.042 .0029516 .1682743 | |
| dep4 <- | ||
| Depress | 1.248634 .055827 22.37 0.000 1.139215 1.358053 | |
| _cons | .0591629 .0665563 0.89 0.374 -.0712852 .1896109 | |
| hlth1 <- | ||
| Health | 1.062984 .0414027 25.67 0.000 .9818361 1.144132 | |
| _cons | -.0424677 .0523266 -0.81 0.417 -.1450259 .0600906 | |
| hlth2 <- | ||
| Health | .4933346 .038082 12.95 0.000 .4186953 .5679738 | |
| _cons | -.0357306 .0398651 -0.90 0.370 -.1138647 .0424035 | |
| hlth3 <- | ||
| Health | .7293404 .0362297 20.13 0.000 .6583315 .8003493 | |
| _cons | .0165731 .0419967 0.39 0.693 -.0657389 .09888515 | |
| hlth4 <- | ||
| Health | 1.273872 .0550442 23.14 0.000 1.165988 1.381757 | |
| _cons | -.0487405 .0668903 -0.73 0.466 -.179843 .0823621 | |
| surv_time | ||
| /ln_p | -.5314218 .0716854 -7.41 0.000 -.6719227 -.390921 | |
| var(Depress) | 1 (constrained) | |
| var(Health) | 1 (constrained) | |
| cov(Health, | ||
| Depress) | .0411 .0495383 0.83 0.407 -.0559932 .1381932 | |
| var(e.dep1) | .2232991 .0293288 .1726185 .2888595 | |
| var(e.dep2) | .5370324 .0357861 .4712802 .6119583 | |
| var(e.dep3) | .3814731 .0282049 .3300113 .4409598 | |
| var(e.dep4) | .6558288 .0570452 .5530335 .7777311 | |
| var(e.hlth1) | .2397716 .0264884 .1930913 .297737 | |
| var(e.hlth2) | .5513769 .0362948 .4846381 .6273062 | |
| var(e.hlth3) | .350238 .0257087 .3033068 .404431 | |
| var(e.hlth4) | .6153669 .0515441 .5221991 .7251571 | |
gsem reports coefficients. Because we fit a Weibull model for surv_time, exponentiated coefficients can be interpreted as hazard ratios and are reported by estat eform.
. estat eform surv_time
| surv_time | exp(b) Std. Err. z P>|z| [95% Conf. Interval] | |
| age | 1.113855 .0133876 8.97 0.000 1.087923 1.140406 | |
| Depress | 3.388543 .3874702 10.67 0.000 2.708198 4.2398 | |
| Health | .1682992 .0256828 -11.68 0.000 .1247921 .2269745 | |
| _cons | .0009591 .0008368 -7.97 0.000 .0001735 .0053026 | |
Depress and age have hazard ratios greater than 1; being more depressed and being older both correspond to increased hazard and thus decreased survival times. Health has a hazard ratio less than 1; better overall health corresponds to increased survival times.
We use margins to compute marginal mean survival times for ages ranging from 70 to 85.
. margins, at(age=(70(3)85)) predict(mu outcome(surv_time)) noatlegend
Adjusted predictions Number of obs = 500
Model VCE : OIM
Expression : Marginal predicted mean (analysis time when record ends),
predict(mu outcome(surv_time))
| Delta-method | ||
| Margin Std. Err. z P>|z| [95% Conf. Interval] | ||
| _at | ||
| 1 | 5.263968 1.965496 2.68 0.007 1.411666 9.116271 | |
| 2 | 3.035966 1.111428 2.73 0.006 .8576069 5.214325 | |
| 3 | 1.750977 .6397585 2.74 0.006 .4970736 3.004881 | |
| 4 | 1.009867 .3749436 2.69 0.007 .2749909 1.744743 | |
| 5 | .5824353 .2233669 2.61 0.009 .1446443 1.020226 | |
| 6 | .3359165 .1348604 2.49 0.013 .0715949 .600238 | |
We can plot these marginal means using marginsplot.
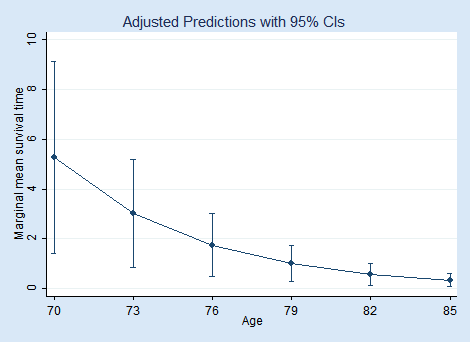
As expected, the predicted marginal mean survival time decreases with age.
You can read more about Stata's new SEM features and see several worked examples in Stata Structural Equation Modeling Reference Manual.
Read the overview from the Stata News.
Upgrade now Order Stata




