
1 item has been added to your cart.
| Title | Display multiple descriptive statistics in separate columns using dtable and collect | |
| Author | Mia Lv, StataCorp |
When you are ready to publish your work, it is common to include a table of descriptive statistics, often referred to as "Table 1". In Stata 18, you can use the dtable command to create these tables and export them to various formats. Here is an example:
. webuse nhanes2l, clear (Second National Health and Nutrition Examination Survey) . dtable age weight bpsystol i.sex i.race, by(diabetes, nototal) export(table1.xlsx, replace)
The exported Excel table looks like
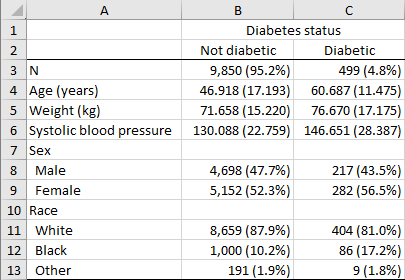
We can see that different summary statistics (mean and standard deviation for continuous variables like age, weight, and bpsystol and frequency and percentages for categorical variables like sex and race) are bundled together in one column for each by() group. This behavior of dtable is intentional because it provides a more compact and uniform table layout. However, we might sometimes prefer that each summary statistic have its own column and header. For instance, we might want to create something like
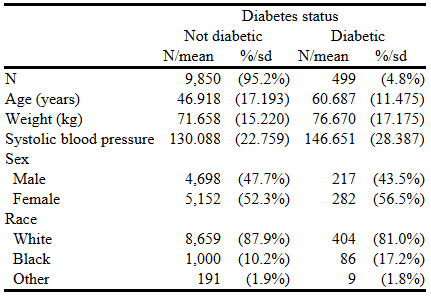
This FAQ will explain how to achieve this.
To customize the default look of tables generated using dtable, it is important to understand the table layout. Let's continue with the example we showed above. After running the dtable command, you can check the table’s layout by typing
. collect layout
Collection: DTable
Rows: var
Columns: diabetes#result
Table 1: 11 x 2
(table omitted)
We can see that the rows are identified by the dimension var and the columns are identified by the interaction between the dimensions diabetes and result (with the levels of result nested within each level of diabetes). If you would like to get a deeper understanding of collect layout, please see FAQ: How do I change a table’s layout using collect layout?
Then let’s check the levels of these dimensions:
. collect levelsof var
Collection: DTable
Dimension: var
Levels: _N _hide age weight bpsystol 1.sex 2.sex 1.race 2.race 3.race
. collect levelsof diabetes
Collection: DTable
Dimension: diabetes
Levels: 0 1
. collect levelsof result
Collection: DTable
Dimension: result
Levels: _dtable_stats _dtable_test frequency fvfrequency fvpercent mean
percent proportion rawpercent rawproportion sd sumw
There is not much to say about the var and diabetes dimensions. However, the result dimension shows many levels, and we notice that not all of them are used in the table (if they were all used, we would have more than just two columns). This suggests that the result dimension has some autolevels that are being used without us specifying the levels. For more detailed information about autolevels, please see FAQ: What are the autolevels of a dimension in a table (collection)?
Now let’s check if result indeed has any autolevels:
. collect query autolevels result
Automatic dimension levels
Collection: DTable
Dimension: result
Levels: _dtable_stats _dtable_test
We see there are two autolevels. However, _dtable_test is empty because we did not request any test using dtable. Therefore, only _dtable_stats is used. It is worth mentioning that _dtable_stats is a composite result, which means it includes multiple results (these are existing levels in the dimension result), but all the elements will be displayed in one cell in the table instead of different cells. We can have a sneak peek at its elements:
. collect query composite _dtable_stats
Composite definition
Collection: DTable
Composite: _dtable_stats
Elements: frequency
percent
mean
sd
fvfrequency
fvpercent
Delimiter: " "
Trim: on
Override: off
We see that result[_dtable_stats] includes six result levels: result[frequency], result[percent], result[mean], result[sd], result[fvfrequency], and result[fvpercent]. These cover all the summary statistics involved in this table. Specifically, result[frequency] and result[percent] correspond to the sample frequency statistics (in the first row for N), result[mean] and result[sd] are the mean and standard deviation for continuous variables, and result[fvfrequency] and result[fvpercent] correspond to the frequency and percentages for the categorical variables. In each row, the available statistics will be displayed. Now that we have fully understood the table layout built by dtable, we can move forward and see how to change it.
Because dtable has already collected all the summary statistics in the collection with proper tags, we do not need to re-collect anything. We can directly call collect layout to build a new table using the layout we prefer. Our first attempt will be replacing result[_dtable_stats] in the original layout with all of its element levels while keeping all other things unchanged:
. collect layout (var) (diabetes#result[frequency percent mean sd fvfrequency fvpercent])
Collection: DTable
Rows: var
Columns: diabetes#result[frequency percent mean sd fvfrequency fvpercent]
Table 1: 11 x 12
| Diabetes status |
| Not diabetic |
| N 9,850 (95.2%) 499 (4.8%) Age (years) 46.918 (17.193) 60.687 (11.475) Weight (kg) 71.658 (15.220) 76.670 (17.175) Systolic blood pressure 130.088 (22.759) 146.651 (28.387) Sex Male 4,698 (47.7%) 217 (43.5%) Female 5,152 (52.3%) 282 (56.5%) Race White 8,659 (87.9%) 404 (81.0%) Black 1,000 (10.2%) 86 (17.2%) Other 191 (1.9%) 9 (1.8%) |
This table is halfway to what we want to see. Each statistic has its own column, but there are many empty cells because each statistic gets a unique column. Please note that if you have the same type of summary statistics for all the variables in the table, you may stop at this step. For example, if you request the mean and standard deviation for all the continuous variables, do not have any categorical variables, and hide the sample frequency statistics, the command will give you the table you desire.
However, in this example, we wish to let mean, frequency, and fvfrequency share the same column and let sd, percent, and fvpercent share the same column so that the table will look more compact. Let’s create two new composite results, column1 and column2, and make them the autolevels for the result dimension:
. collect composite define column1 = frequency mean fvfrequency . collect composite define column2 = percent sd fvpercent . collect style autolevels result column1 column2, clear
Now let’s add labels for the new composite results and use the simple layout again. Because we have declared the autolevels for result, we do not need to type its levels in the layout.
. collect label levels result column1 "N/mean" column2 "%/sd", modify . collect style header result , level(label) . collect layout (var) (diabetes#result)
The final table looks like
| Diabetes status |
| Not diabetic Diabetic |
| N/mean %/sd N/mean %/sd |
| N 9,850 (95.2%) 499 (4.8%) Age (years) 46.918 (17.193) 60.687 (11.475) Weight (kg) 71.658 (15.220) 76.670 (17.175) Systolic blood pressure 130.088 (22.759) 146.651 (28.387) Sex Male 4,698 (47.7%) 217 (43.5%) Female 5,152 (52.3%) 282 (56.5%) Race White 8,659 (87.9%) 404 (81.0%) Black 1,000 (10.2%) 86 (17.2%) Other 191 (1.9%) 9 (1.8%) |
Here is the complete code that combines all the steps:
clear all webuse nhanes2l, clear dtable age weight bpsystol i.sex i.race, by(diabetes, nototal) export(table1.xlsx, replace) * put each statistic in a unique column collect layout (var) (diabetes#result[frequency percent mean sd fvfrequency fvpercent]) * define new composite results that split results into 2 columns collect composite define column1 = frequency mean fvfrequency collect composite define column2 = percent sd fvpercent * redefine result autolevels collect style autolevels result column1 column2, clear * label the new composite results collect label levels result column1 "N/mean" column2 "%/sd", modify * show the new result labels in the header collect style header result, level(label) * back to the simple layout collect layout (var) (diabetes#result)





