
1 item has been added to your cart.
Unicode is the modern way that computers encode characters such a/s the letters in the words you are now reading. Unicode encodes all the world's characters, meaning we can write Hello, Здравствуйте, こんにちは, and a lot more.
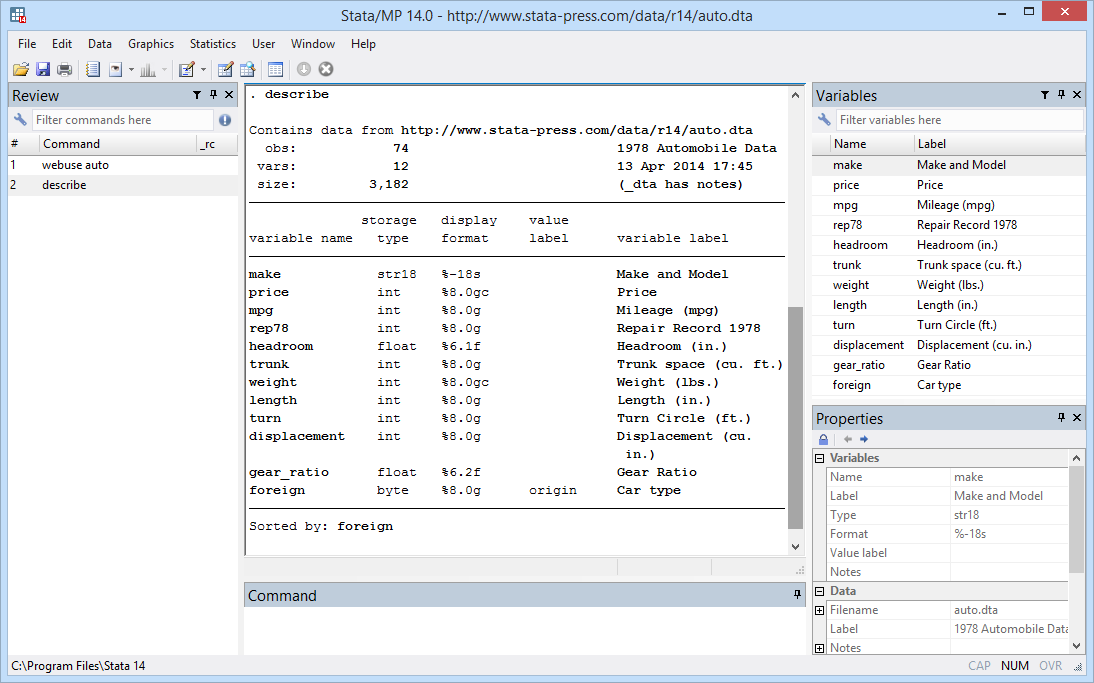
Stata now supports Unicode, and you can use the full range of characters everywhere. Thus, a dataset created in English might look like this:
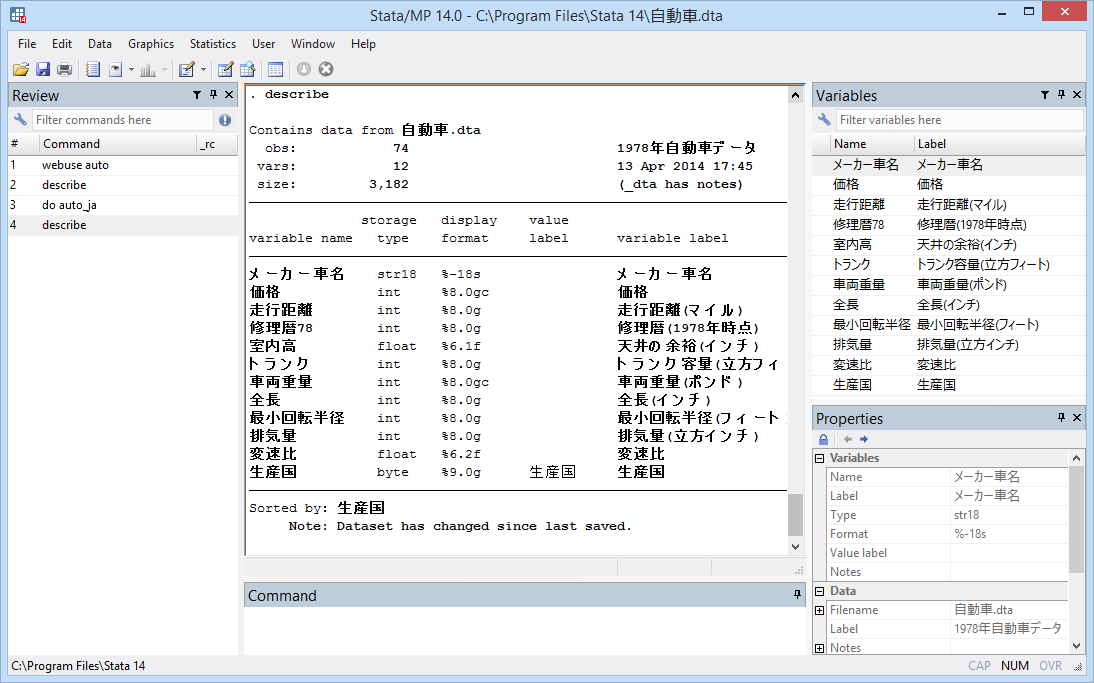
The same dataset created in Japanese might look like this:
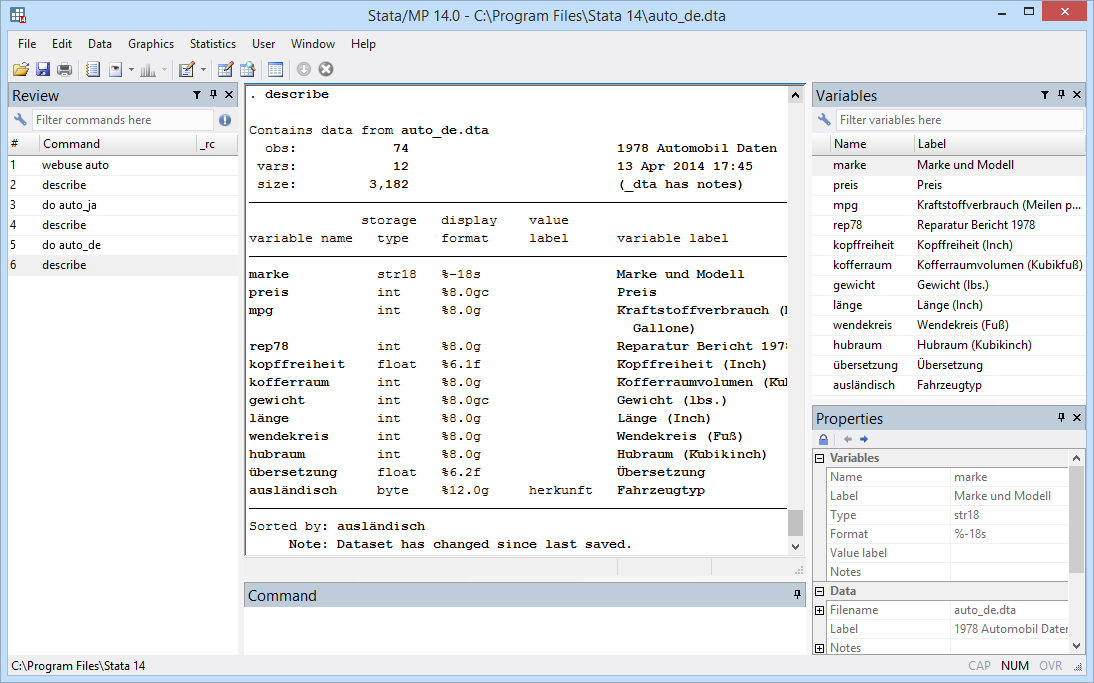
And the same dataset created in German might look like this:
You may use Unicode in variable names, in labels, and of course in the string variables of your data.
That you can include Unicode in your data is important because data come as they come. Regardless of the language of the data, you can make your output instantly more readable by setting the variable and value labels in the language of your audience. And, if you wish, you can use the full range of Unicode characters for your variable names, notes, and the like.
Unicode literally puts all the world's characters at your fingertips.
Read more about Unicode support in Stata Data Management Reference Manual; see [D] unicode.
Read the overview from the Stata News.
Upgrade now Order Stata




