

In the spotlight: Estimating, graphing, and interpreting interactions using margins
After we fit a model, the effects of covariate interactions are of special interest. With margins and factor-variable notation, I can easily estimate, graph, and interpret effects for models with interactions. This is true for linear models and for nonlinear models such as probit, logistic, and Poisson. Below, I illustrate how this works.
Factor-variable notation makes my life easier
Suppose I want to fit a model that includes the interactions between continuous variables, between discrete variables, or between a combination of the two. I do not need to create dummy variables, interaction terms, or polynomials. I just use factor-variable notation.
If I want to include the square of a continuous variable x in my model, I type
c.x#c.x
If I want a third-order polynomial, I type
c.x#c.x#c.x
If I want to use a discrete variable a with five levels, I do not need to create a dummy variable for four categories. I simply type
i.a
If I want to include x, a, and their interaction in my model, I type
c.x##i.a
Stata now understands which variables in my model are continuous and which variables are discrete. This matters when I am computing effects. If I am interested in marginal effects for a continuous variable on an outcome of interest, the answer is a derivative. If I am interested in the effect for a discrete variable on an outcome, the answer is a discrete change relative to a base level. After fitting a model with discrete variables and interactions specified in this way with margins, I automatically get the effects I want.
margins and factor variables in action
Suppose I am interested in modeling the probability of an individual being married as a function of years of schooling (education), the percentile of income distribution to which that individual belongs (percentile), the number of times he or she has been divorced (divorces), and whether his or her parents are divorced (pdivorced).
I fit the model like this:
. probit married c.education##c.percentile c.education#i.divorces
i.pdivorced##i.divorces
Factor-variable notation helps me introduce the continuous variables education and percentile; the discrete variables divorces and pdivorced; and the interactions between education and percentile, education and divorces, and divorces and pdivorced. Stata reports
Probit regression Number of obs = 5,000
LR chi2(10) = 387.39
Prob > chi2 = 0.0000
Log likelihood = -3039.8093 Pseudo R2 = 0.0599
| married | Coef. Std. Err. z P>|z| [95% Conf. Interval] | |
| education | .0353678 .0106325 3.33 0.001 .0145285 .0562072 | |
| percentile | .3778494 .6261062 0.60 0.546 -.8492962 1.604995 | |
| c.education# | ||
| c.percentile | .2664662 .0670821 3.97 0.000 .1349876 .3979447 | |
| divorces# | ||
| c.education | ||
| one | .0022121 .0180872 0.12 0.903 -.033238 .0376623 | |
| two | .1164978 .0697084 1.67 0.095 -.0201281 .2531237 | |
| pdivorced | ||
| divorced | -.0689176 .0426699 -1.62 0.106 -.1525491 .0147138 | |
| divorces | ||
| one | .1407711 .1840464 0.76 0.444 -.2199532 .5014953 | |
| two | -1.403379 .7110954 -1.97 0.048 -2.797101 -.0096579 | |
| pdivorced# | ||
| divorces | ||
| divorced # | ||
| one | -.4587328 .1010328 -4.54 0.000 -.6567534 -.2607122 | |
| divorced # | ||
| two | -.0595618 .3206616 -0.19 0.853 -.688047 .5689234 | |
| _cons | -.1947775 .105829 -1.84 0.066 -.4021985 .0126434 | |
Using the results from my probit model, I can estimate the average change in the probability of being married as the interacted variables divorces and education both change. To get the effect I want, I type
. margins divorces, dydx(education) pwcompare
The dydx(education) option computes the average marginal effect of education on the probability of divorce, while the divorces statement after margins paired with the pwcompare option computes the discrete differences between the levels of divorce. Stata reports
Pairwise comparisons of average marginal effects Model VCE : OIM Expression : Pr(married), predict() dy/dx w.r.t. : education
| Contrast Delta-method Unadjusted | ||
| dy/dx Std. Err. [95% Conf. Interval] | ||
| education | ||
| divorces | ||
| one vs none | .0012968 .0061667 -.0107897 .0133833 | |
| two or more vs none | .0403631 .0195432 .0020591 .0786672 | |
| two or more vs one | .0390664 .0201597 -.0004458 .0785786 | |
The average marginal effect of education is 0.040 higher when everyone is divorced two times instead of everyone being divorced zero times. The difference in the average marginal effect of education when everyone is divorced one time versus when everyone is divorced zero times is 0.001. This difference is not significantly different from 0. The same is true when everyone is divorced two times instead of everyone being divorced one time.
What I did above was to change both education and pdivorce simultaneously. In other words, to get the interaction effect, I computed a cross or double derivative (technically, for the discrete variable, I do not have a derivative but a difference with respect to the base level for the discrete variables).
This way of tackling the problem is unconventional. What is usually done is to compute the derivative with respect to the continuous variable, evaluate it at different values of the discrete covariate, and graph the effects. If we do this, we get
. margins, dydx(education) at(divorces==0) at(divorces==1) at(divorces==2) Average marginal effects Number of obs = 5,000 Model VCE : OIM Expression : Pr(married), predict() dy/dx w.r.t. : education 1._at : divorces = 0 2._at : divorces = 1 3._at : divorces = 2
| Delta-method | ||
| dy/dx Std. Err. z P>|z| [95% Conf. Interval] | ||
| education | ||
| _at | ||
| 1 | .0217072 .0026107 8.31 0.000 .0165904 .0268239 | |
| 2 | .0230039 .0055898 4.12 0.000 .0120481 .0339597 | |
| 3 | .0620703 .0193699 3.20 0.001 .024106 .1000346 | |
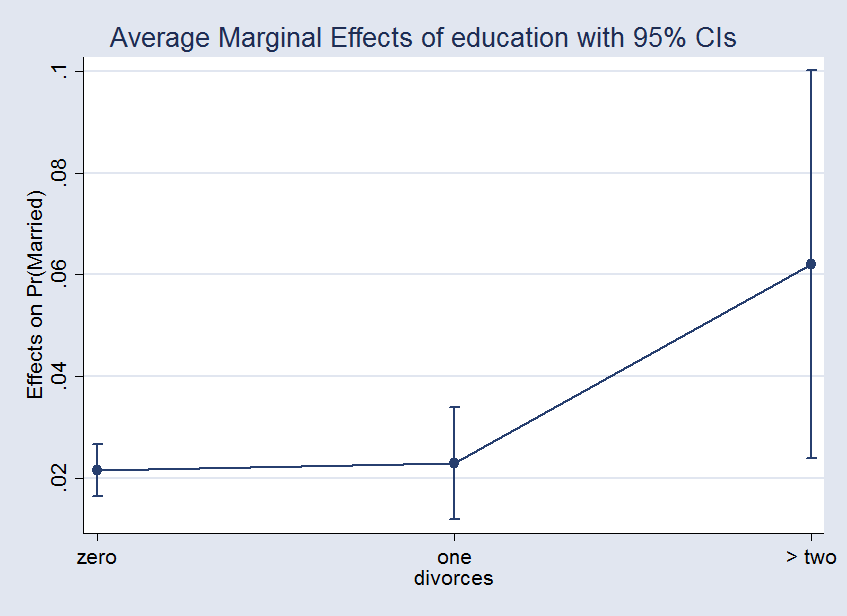
To get the effects from the previous example, I only need to take the differences between the different effects. For instance, the first interaction effect is the difference of the first and second margins, 0.023 − 0.022 = 0.001.
What have we learned?
We can use margins and factor-variable notation to estimate and graph interaction effects. In the example above, I computed an interaction effect between a continuous and a discrete covariate, but I can also use margins to compute interaction effects between two continuous or two discrete covariates, as is shown in this blog article.
— Enrique Pinzón
Senior Econometrician, StataCorp LP





