
1 item has been added to your cart.
Structural equation modeling (SEM) was introduced in Stata 12.
Order |
If you don’t know what SEM is, go here.
View the complete list of SEM capabilities
SEM stands for structural equation modeling. SEM is a notation for specifying structural equations, a way of thinking about them, and methods for estimating their parameters.
SEM encompasses a broad array of models from linear regression to measurement models to simultaneous equations, including along the way confirmatory factor analysis (CFA), correlated uniqueness models, latent growth models, and multiple indicators and multiple causes (MIMIC).
Stata’s new sem command fits SEMs.
Enter your model graphically,
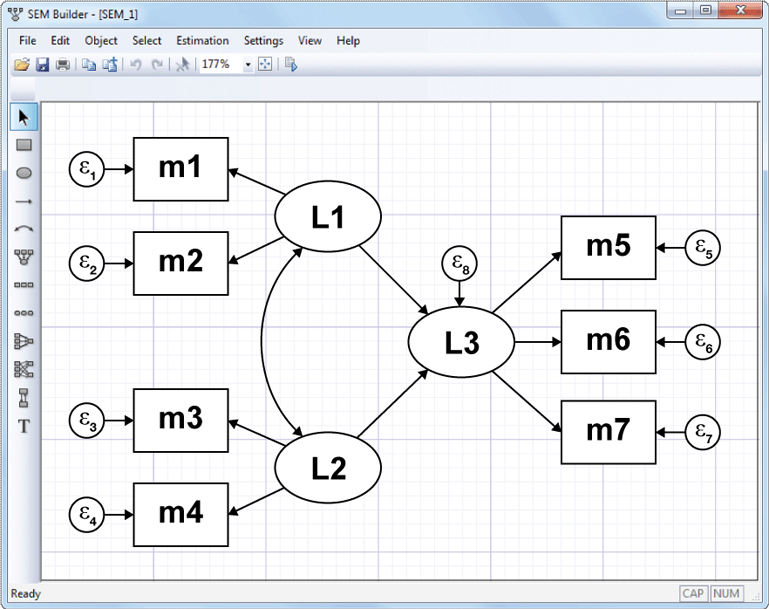
or use the command syntax
. sem (L1 -> m1 m2)
(L2 -> m3 m4)
(L3 <- L1 L2)
(L3 -> m5 m6 m7)
It’s the same model either way.
Stata’s GUI uses standard path notation.
In command syntax, you type the path diagram. Capitalized names are latent variables. Lowercased names are observed variables. You can type arrows in either direction. The above model could be equally well typed as
. sem (m1 m2 <- L1)
(L2 -> m3 m4)
(L3 <- L1 L2)
(L3 -> m5 m6 m7)
and order does not matter, and neither does spacing:
. sem (m1 m2 <- L1) (L2 -> m3 m4) (L3 -> m5 m6 m7) (L3 <- L1 L2)
You can specify paths individually,
. sem (m1 <- L1) (m2 <- L1) (L2 -> m3) (L2 -> m4) (L3 -> m5) (L3 -> m6) (L3 -> m7) (L3 <- L1) (L3 <- L2)
or combined,
. sem (m1 m2 <- L1) (L2 -> m3 m4) (L3 -> m5 m6 m7) (L3 <- L1 L2)
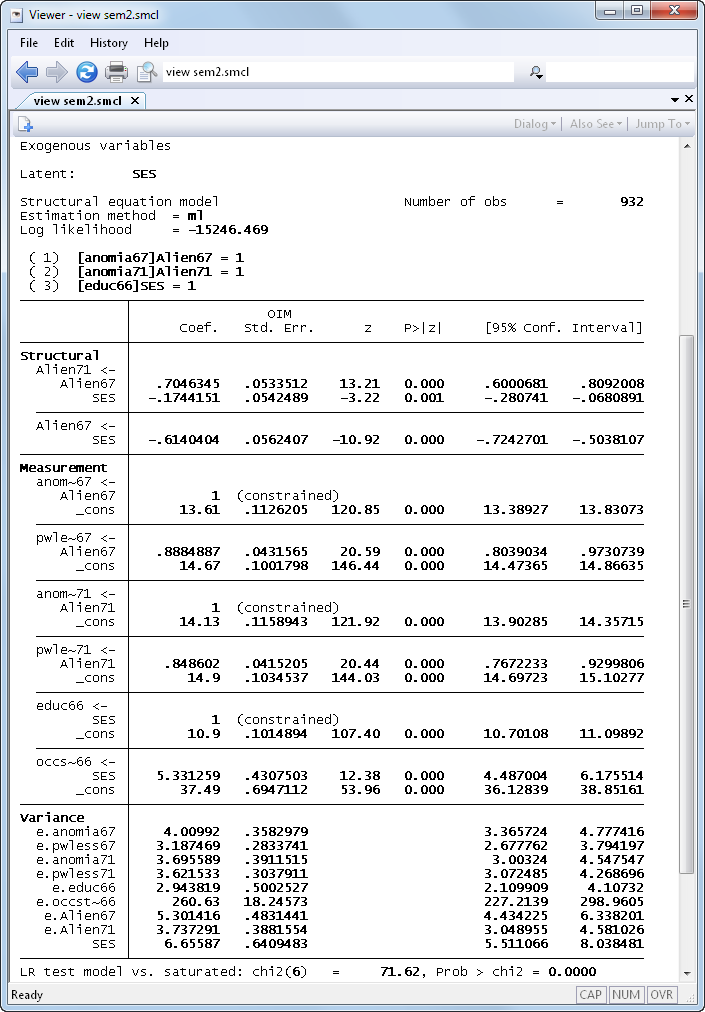
Let’s fit a structural model with a measurement component using data from Wheaton, Muthén, Alwin, and Summers (1977):
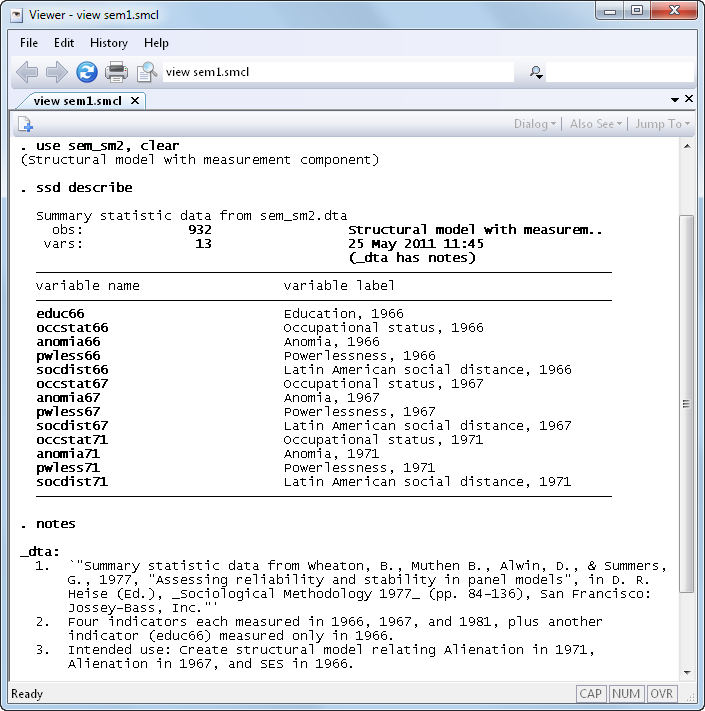
Below we will demonstrate
Simplified versions of the model fit by the authors of the referenced paper appear in many SEM software manuals. One simplified model is
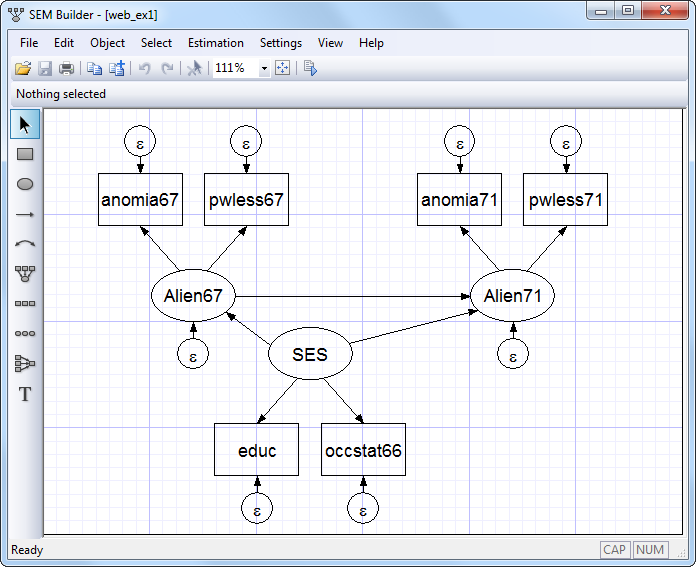
You can also readily fit this model using the following command:
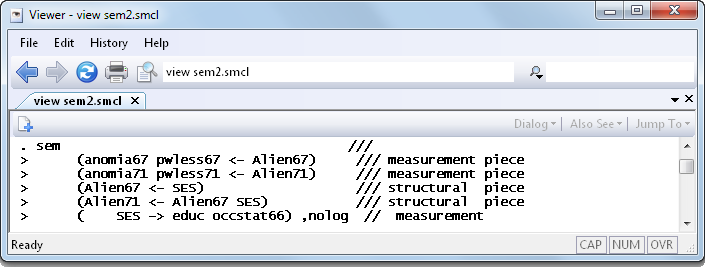
And the results are
Notes:
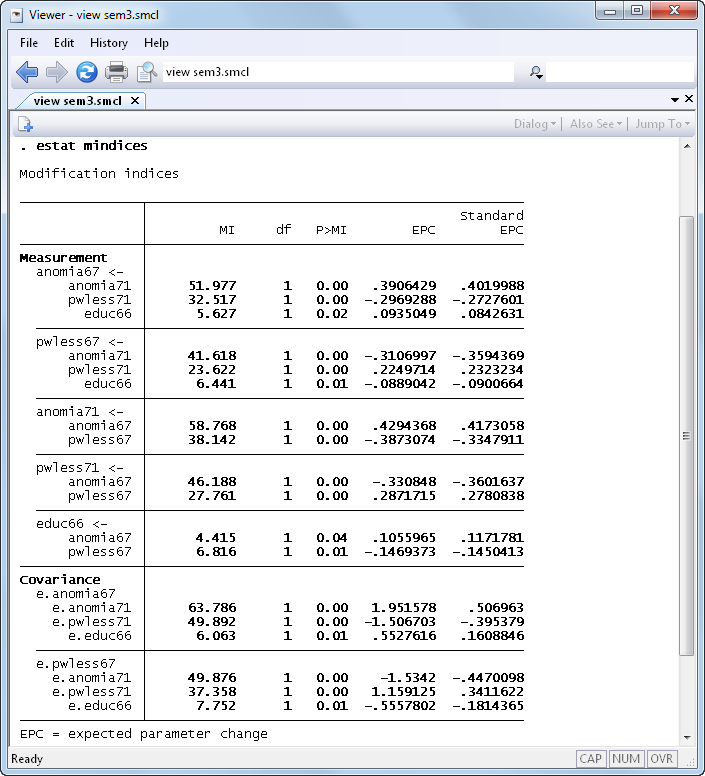
That the model is a poor fit leads us to looking at the modification indices:
Notes:
Let’s refit the model and include those two previously excluded covariances:
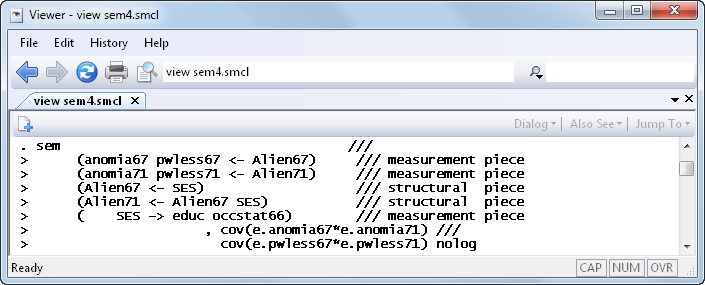
And the results are
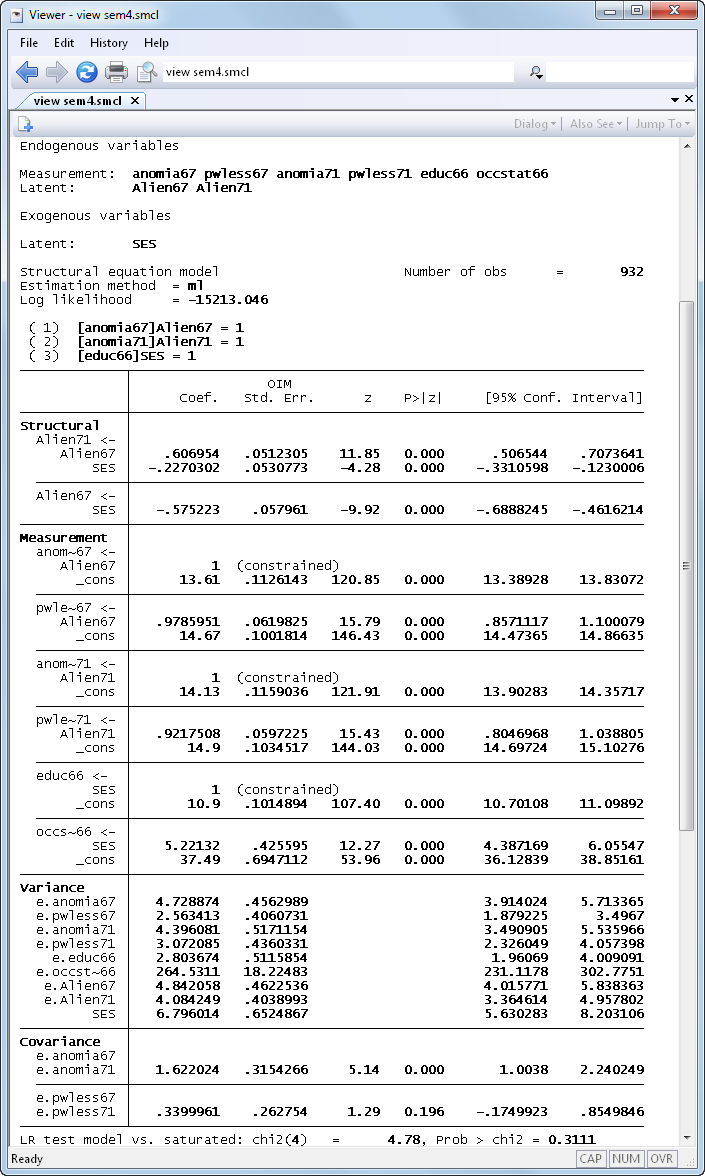
Notes:
See New in Stata 19 to learn about what was added in Stata 19.




