
1 item has been added to your cart.
Do you know what SEM is? (If you know what SEM is, read an overview of Stata’s SEM features.)
SEM stands for structural equation modeling. SEM is
Stata’s sem implements linear structural equation models. gsem provides extensions to linear SEMs that allow for generalized-linear models and multilevel models.
For those of you unfamiliar with SEM, it is worth your time to learn about it if you ever fit linear regressions, multivariate linear regressions, seemingly unrelated regressions, or simultaneous systems, or if you are interested in generalized method of moments (GMM). With the generalizations provided by gsem, it is also worth your time to learn about SEM if you ever fit models with binary, count, ordinal, or nominal responses or if you ever fit multilevel mixed-effects models, selection models, or endogenous treatment-effects models.
Here, we provide an introduction to linear SEM, which is based on the linear model. What it brings to the table is flexible specification—nearly anything can be allowed to be correlated or constrained to be uncorrelated—and unobserved (latent) variables which can be treated (almost) as if they were observed.
sem fits the first and second moments of the distribution of observed variables—means, variances, and covariances—rather than fitting the observed values themselves. Both maximum likelihood and GMM methods are available; sem uses a weighting matrix corresponding to asymptotic distribution free estimation in the SEM literature.
You still think of the model in the same way as usual, but in a model like
yj = β0 + β1x1j + ... + βkxkj + ej
let’s now call ej the error. Reserve the word residual for the true residuals of the SEMs, which are the differences between the observed and predicted moments.
When sem is used to fit models that can be fit by the other linear estimators, results are the same, asymptotically the same—by which we mean different in finite samples, and there is no theoretical reason to prefer one set of estimated results to the other—or the SEM results are asymptotically the same and the sem results should be better in finite samples because of theoretical reasons.
Individual structural equation models are usually described using path diagrams, such as
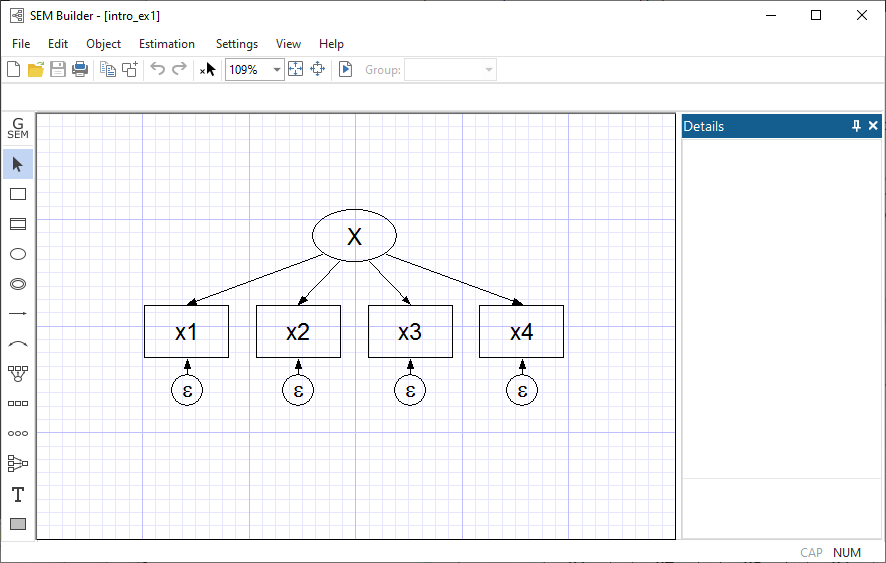
This diagram is composed of
Thus the above figure corresponds to the equations
x1 = α1 + β1X + e.x1
x2 = α2 + β2X + e.x2
x3 = α3 + β3X + e.x3
x4 = α4 + β4X + e.x4
There’s a third way of writing this model, namely
(x1<-X) (x2<-X) (x3<-X) (x4<-X)
This is the way we could write the model if we wanted to use sem’s command syntax rather than drawing the model in sem’s GUI. The full command we would type would be
. sem (x1<-X) (x2<-X) (x3<-X) (x4<-X)
However we write this model, what is it? It is a measurement model, a term loaded with meaning for some researchers. X might be mathematical ability. x1, x2, x3, and x4 might be scores from tests designed to measure mathematical ability. x1 might be the score based on your answers to a series of questions after reading this section.
The model we have just drawn, written in mathematical notation, or written in Stata command notation can be interpreted in other ways too. Look at this diagram:
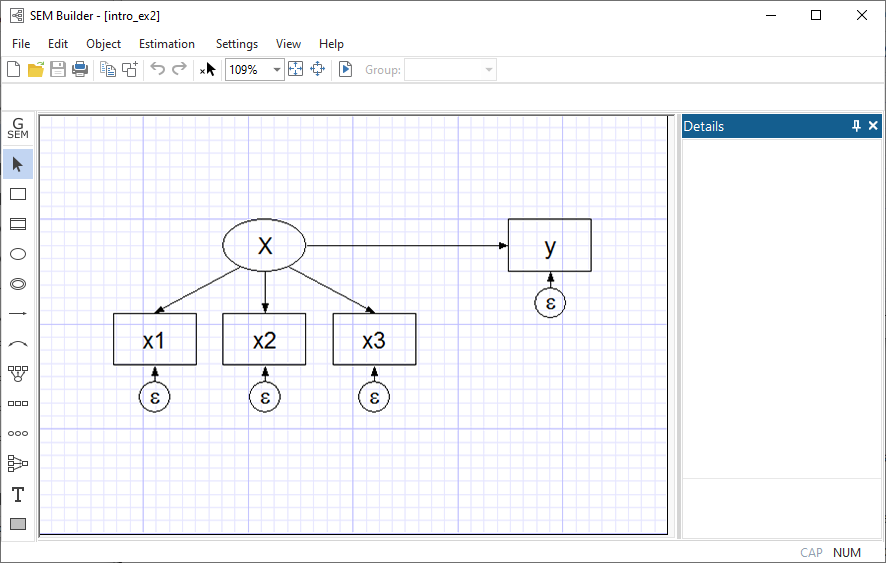
Despite appearances, this diagram is identical to the previous diagram except that we have renamed x4 to be y. The fact that we changed a name obviously does not matter substantively. That fact that we have rearranged the boxes in the diagram is irrelevant, too; paths connect the same variables in the same directions. The equations for the above diagrams are the same as the previous equations with the substitution of y for x4:
x1 = α1 + β1X + e.x1
x2 = α2 + β2X + e.x2
x3 = α3 + β3X + e.x3
y = α4 + β4X + e.y
The Stata command notation changes similarly,
(x1<-X) (x2<-X) (x3<-X) (y<-X)
Many people looking at the model written in this way might decide that it is not a measurement model but a measurement error model. y depends on X, but we do not observe X. We do observe x1, x2, and x3, each a measurement of X but with error. Our interest is in knowing β4, the effect of true X on y.
A few others might disagree and instead see a model for interrater agreement. Obviously we have four raters who each make a judgment, and we want to know how well the judgment process works and how well each of these raters perform.
You are now ready to return to our description of Stata’s sem command, but before you do, let us show you an example we think will appeal to you.
In our documentation, we have an example of a single-factor measurement model, which is demonstrated using the following data:
| Variable | Obs Mean Std. dev. Min Max | |
| x1 | 500 99.518 14.35402 60 137 | |
| x2 | 500 99.954 14.1939 52 140 | |
| x3 | 500 99.052 14.26395 59 150 | |
| x4 | 500 94.474 70.11603 -113 295 | |
As we mentioned above, if we rename variable x4 to be y, we can reinterpret this measurement model as a measurement error model. In this interpretation, X is the unobserved true value. x1, x2, and x3 are each measurements of X, but with error. Meanwhile, y (x4) is really something else entirely. Perhaps y is earnings, and we believe
y = α4 + β4X + e.y
We are interested in β4, the effect of true X on y.
If we were to go back to the data and type regress y x1, we would obtain an estimate of β4, but we would expect that estimate to be biased toward zero because of the errors-in-variable problem. The same applies for y on x2 and y on x3. If we do that, we obtain
β4 based on regress y x1 4.09
β4 based on regress y x2 3.71
β4 based on regress y x3 3.70
In the example in our manual, we fit
. sem (x1<-X) (x2<-X) (x3<-X) (y<-X)
and we obtained
β4 based on sem (y<-X) 6.89
That β4 might be 6.89 seems plausible because we expect the estimate to be larger than the estimates we obtain using the variables measured with error. In fact, we can tell you that the 6.89 estimate is quite good because we at StataCorp know that the true value of β4 is 7.
Now you can return to our description of Stata's linear structural equation modeling (SEM) features. If you are interested in multilevel modeling or models with binary, count, ordinal, or nominal response variables, you will also want to see the description of the generalized SEM features.




