
1 item has been added to your cart.
Updates to factor variables were introduced in Stata 11.
|
| Order |
Stata now handles factor (categorical) variables elegantly. You can now prefix a variable with i. to specify indicators for each level (category) of the variable. You can put a # between two variables to create an interaction–indicators for each combination of the categories of the variables. You can put ## instead to specify a full factorial of the variables—main effects for each variable and an interaction. If you want to interact a continuous variable with a factor variable, just prefix the continuous variable with c.. You can specify up to eight-way interactions.
We run a linear regression of cholesterol level on a full factorial of age group and whether the person smokes along with a continuous body mass index (bmi) and its interaction with whether the person smokes.
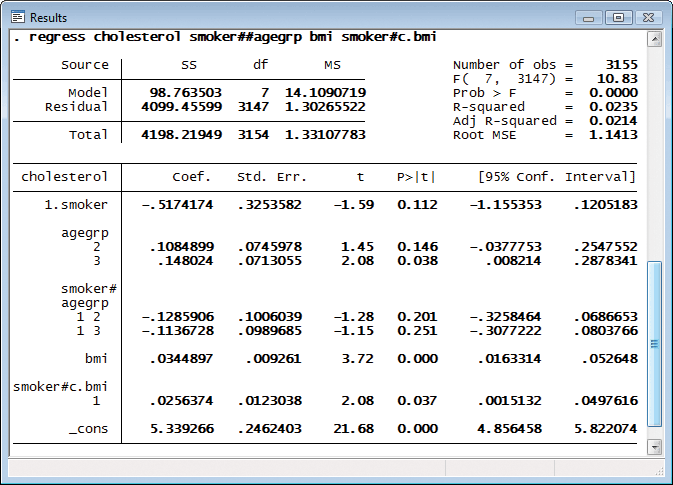
We could have used parenthesis binding, to type the same model more briefly:
. regress cholesterol smoker##(agegrp c.bmi)
Base levels can be changed on the fly: i.agegrp uses the default base level of 1, whereas b3.agegrp makes 3 the base level.
The level indicator variables are not created in your dataset, saving lots of space.
Factor variables are integrated deeply into Stata’s processing of variable lists, providing a consistent way of interacting with both estimation and postestimation commands.
For a complete list of new general statistics features in Stata 11, click here.




