Michael Binder (Dynamic panel data models with homogeneous slopes) shows that
the bias in the dynamic FE models is equal to
(Embedded image moved to file: pic25996.jpg) where � is the true coefficient,
and AT and BT complicated expressions that tend respectively to 0 and 1 when the
time dimension T tends to infinity. Consequently, with a very large T (say, more
than 50), the bias is quasi non-existent. However, I had T>150 and one of the
referees strongly complained why I am using FE, and not Arellano-Bond.
Branko
Development Research, World Bank
Email: [email protected] or branko_mi@yahoo.
tel: 202-473-6968
World Bank, Room MC 3-581
1818 H Street NW
Washington D.C. 20433
For "Worlds Apart" see
http://www.pupress.princeton.edu/titles/7946.html
Website:
http://econ.worldbank.org/projects/inequality
For papers see also:
http://econpapers.hhs.se/
http://papers.ssrn.com/sol3/cf_dev/AbsByAuth.cfm?per_id=149002
Michael Hanson
<[email protected]
om> To
Sent by: [email protected]
owner-statalist cc
@hsphsun2.harva
rd.edu Subject
Re: st: using xtabond and xtabond2
07/28/2007
07:55 PM
Please respond
to
statalist@hsphs
un2.harvard.edu
On Jul 28, 2007, at 6:56 PM, natalie chan wrote:
> Maybe this is a question more about econometrics than about Stata but
> I can't find anywhere more appropriate to ask this question. Thanks in
> advance.
>
> I am doing regressions on economic growth equations with a panel data
> of 20 years for 48 countries. I wanted to use dynamic panel approach
> with xtabond or xtabond2, however, the Arellano-Bond methods are
> specified for data with small T and large N. On the other hand, I
> have seen some researchers using Arellano-Bond methods on growth
> models, including Bond himself. Could anyone give me some advice on
> this? Thanks a lot.
I would like to expand Natalie's question: I have an application
of
dynamic panel data in which T/N is nearly 3, with N = 50. In David
Roodman's excellent discussion of -xtabond2- [1], he writes, "If T is
large, dynamic panel bias becomes insignificant, and a more
straightforward fixed effects estimator works." (p. 42) However, I
have never been able to find a discussion of how "large" of a T is
"large enough" in the literature (which I interpret is part of
Natalie's question). In the only textbook reference I have found,
Baltagi (2005) [2] writes, "FE, GMM, and LIML exhibit a bias term in
their asymptotic distributions; the biases are of the order 1/T, 1/N,
and 1/(2N-T), respectively." (p. 153)
Would it be reasonable, therefore, to conclude that in Natalie's
case (T/N < 1/2), GMM (i.e. AB-type estimators) or LIML would be
preferred, whereas in my case (T/N > 2.5), FE would be preferred? (I
realize that this claim is based on asymptotic arguments, and that
the N & T discussed here are probably too small. Any information
about the small-sample properties of these estimators in a dynamic
panel context would be appreciated as well.)
I also recognize that this question is at least as much about
statistics (econometrics) as about Stata, and I appreciate any help
or suggestions.
[1] <http://repec.org/nasug2006/howtodoxtabond2.cgdev.pdf>
[2] <http://www.stata.com/bookstore/eapd.html>
-- Mike
*
* For searches and help try:
* http://www.stata.com/support/faqs/res/findit.html
* http://www.stata.com/support/statalist/faq
* http://www.ats.ucla.edu/stat/stata/
Attachment:
pic25996.jpg
Description: JPEG image

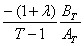{kind=link}