1 item has been added to your cart.
Panel data
Take full advantage of the extra information that panel data provide while
simultaneously handling the peculiarities of panel data. Study the
time-invariant features within each panel, the relationships across panels,
and how outcomes of interest change over time.
Fit linear models or nonlinear
models for binary, count, ordinal, censored, or survival outcomes with
fixed-effects, random-effects, or population-averaged estimators. Fit dynamic
models or models with endogeneity. Fit Bayesian panel-data models.
Multilevel mixed-effects models
Whether the groupings in your data arise in a nested fashion (cities nested
in states and states nested in regions) or in a nonnested fashion (regions
crossed with occupations), you can fit a multilevel model to account for the
lack of independence within these groups.
Fit models for continuous, binary,
count, ordinal, and survival outcomes. Estimate variances of random
intercepts and random coefficients. Compute intraclass correlations. Predict
random effects. Estimate relationships that are population averaged over the
random effects.
Causal inference
Estimate experimental-style causal effects from observational data. With
Stata's treatment-effects estimators, you can use a potential-outcomes
(counterfactuals) framework to estimate, for instance, the effect of
family structure on child development or the effect of unemployment on
anxiety. Fit models for continuous, binary, count, fractional, and
survival outcomes with binary or multivalued treatments using
inverse-probability weighting (IPW), propensity-score matching,
nearest-neighbor matching, regression adjustment, or doubly robust
estimators. If the assignment to a treatment is not independent of the
outcome, you can use an endogenous treatment-effects estimator. In the
presence of group and time effects, you can use
difference-in-differences (DID) and triple-differences (DDD) estimators.
In the presence of high-dimensional covariates, you can use lasso. If
causal effects are mediated through another variable, use causal
mediation with mediate to
disentangle direct and indirect effects.
Multiple imputation
Account for missing data in your sample using multiple imputation. Choose from
univariate and multivariate methods to impute missing values in continuous,
censored, truncated, binary, ordinal, categorical, and count variables.
Then, in a single step, estimate parameters using the imputed datasets, and combine
results. Fit a linear model, logit model, Poisson model, hierarchical model,
survival model, or one of the many other supported models. Use the mi command,
or let the Control Panel interface guide you through your entire MI analysis.
Structural equation modeling (SEM)
Estimate mediation effects, analyze the relationship between an unobserved
latent concept such as conservatism and the observed variables that
measure conservatism, model a system with many endogenous variables and
correlated errors, or fit a model with complex relationships among both latent
and observed variables.
Fit models with continuous, binary, count, ordinal,
fractional, and survival outcomes. Even fit multilevel models with groups of
correlated observations such as children within the same schools. Evaluate
model fit. Compute indirect and total effects. Fit models by drawing a path
diagram or using the straightforward command syntax.
Time series
Handle the statistical challenges inherent to time-series
data—autocorrelations, common factors, autoregressive conditional
heteroskedasticity, unit roots, cointegration, and much more. Analyze
univariate time series using ARIMA, ARFIMA, Markov-switching models,
ARCH and GARCH models, and unobserved-components models. Compare ARIMA
or ARFIMA models using AIC, BIC, and HQIC, and select the best
number of autoregressive and moving-average terms. Analyze multivariate
time series using VAR, structural VAR, VEC, multivariate GARCH,
dynamic-factor models, and state-space models. Compute and graph impulse
responses. Test for unit roots. Perform Bayesian
time-series analysis.
Linear, binary, and count regressions
Fit classical linear models of the relationship between a continuous outcome,
such as wage, and the determinants of wage, such as education level, age,
experience, and economic sector.
If your response is binary (for example,
employed or unemployed), ordinal (education level), count (number of
children), or censored (ticket sales in an existing venue), don't worry. Stata
has maximum likelihood estimators—probit, ordered probit, Poisson, tobit,
and many others—that estimate the relationship between such outcomes and
their determinants. A vast array of tools is available to analyze such models.
Predict outcomes and their confidence intervals. Test equality of parameters
or any linear or nonlinear combination of parameters.
Forecasting
Build multiequation models, and produce forecasts of levels, trends, rates,
etc. Whether you have a small model with a few equations or a complete model
of the economy with thousands of equations, Stata can help you build that
model and produce forecasts.
Your model can include both estimated
relationships and known identities. You can easily create and compare
forecasts under different scenarios, create static and dynamic forecasts, and
even estimate stochastic confidence intervals. You can create your model by
using an intuitive command syntax or by using the interactive forecasting
control panel.
Marginal means, contrasts, and interactions
Marginal effects and marginal means let you analyze and visualize the
relationships between your outcome variable and your covariates, even when
that outcome is binary, count, ordinal, categorical, or censored (tobit).
Estimate population-averaged marginal effects, or evaluate marginal effects at
interesting or representative values of the covariates. Analyze the effect of
interactions. You can even trace out the marginal effect over a range of
interesting covariate values or covariate interactions. You can do all of
this with marginal means, sometimes called potential-outcome means, too—even
when your "mean" is a probability of a positive outcome or a count from a
Poisson model. If you have panel data and random effects, these effects are
automatically integrated out to provide marginal (that is, population-averaged)
effects.
Meta-analysis
Combine results of multiple studies to estimate an overall effect. Use
forest plots to visualize results. Use subgroup analysis and
meta-regression to explore study heterogeneity. Use funnel plots and
formal tests to explore publication bias and small-study effects. Use
trim-and-fill analysis to assess the impact of publication bias on
results. Perform cumulative and leave-one-out meta-analysis. Perform
univariate, multilevel, and multivariate meta-analysis. Use the meta suite, or let the Control Panel interface
guide you through your entire meta-analysis.
Bayesian analysis
Fit Bayesian regression models using one of the Markov chain Monte Carlo
(MCMC) methods. You can choose from various supported models or even
program your own. Extensive tools are available to check convergence,
including multiple chains. Compute posterior mean estimates and credible
intervals for model parameters and functions of model parameters. You
can perform both interval- and model-based hypothesis testing. Compare
models using Bayes factors. Compute model fit using posterior predictive
values and generate predictions. If you want to account for model
uncertainty in your regression model, use
Bayesian model averaging.
Lasso
Use lasso and elastic net for model selection and prediction. And when
you want to estimate effects and test coefficients for a few variables
of interest, inferential methods provide estimates for these variables
while using lassos to select from among a potentially large number of
control variables. You can even account for endogenous covariates.
Whether your goal is model selection, prediction, or inference, you can
use Stata's lasso features with your continuous, binary, count, or
time-to-event outcomes.
Programming
Want to program your own commands to perform estimation,
perform data management, or implement other new features?
Stata is programmable, and thousands of Stata users have
implemented and published thousands of community-contributed commands.
These commands look and act just like official Stata commands
and are easily installed for free over the Internet from within
Stata. A unique feature of Stata's programming environment is Mata,
a fast and compiled language with support for matrix types. Of course, it has
all the advanced matrix operations you need. It also has access to
the power of LAPACK. What's more, it has built-in solvers and optimizers
to make implementing your own maximum likelihood, GMM, or other
estimators easier. And you can leverage all of Stata's estimation and
other features from within Mata. Many of Stata's official commands are
themselves implemented in Mata.
PyStata—Python integration
Interact Stata code with Python code. You can seamlessly pass data and results
between Stata and Python. You can use Stata within Jupyter Notebook and other
IPython environments. You can call Python libraries such as NumPy, matplotlib,
Scrapy, scikit-learn, and more from Stata. You can use Stata analyses from
within Python.
Endogeneity and selection
When explanatory variables are related to omitted observable variables, or
when they are related to unobservable variables, or when there is selection
bias, then causal relationships are confounded, and parameter estimates from
standard estimators produce inconsistent estimates of the true relationships.
Stata can fit consistent models when there is such endogeneity or selection—whether your outcome variable is continuous, binary, count, or ordinal and
whether your data are cross-sectional or panel. Stata can even combine endogenous covariates,
selection, and treatment effects in the same model.
Survival analysis
Analyze duration outcomes—outcomes measuring the time to an event
such as failure or death—using Stata's specialized tools for
survival analysis. Account for the complications inherent in survival
data, such as sometimes not observing the event (right-, left-, and
interval-censoring), individuals entering the study at differing times
(delayed entry), and individuals who are not continuously observed
throughout the study (gaps). You can estimate and plot the probability
of survival over time. Or model survival as a function of covariates
using Cox, Weibull, lognormal, and other regression models. Predict
hazard ratios, mean survival time, and survival probabilities. Do you
have groups of individuals in your study? Adjust for within-group
correlation with a random-effects or shared-frailty model. If you have
many potential covariates, use lasso
cox and elasticnet cox for
model selection and prediction.
Automated reporting and dynamic document generation
Stata is designed for reproducible research, including the ability to
create dynamic documents incorporating your analysis results. Create
Word or PDF files, populate Excel worksheets with results and format
them to your liking, and mix Markdown, HTML, Stata results, and Stata
graphs, all from within Stata. Create tables that compare regression results or summary statistics, use default styles
or apply your own, and export your tables to Word, PDF, HTML, LaTeX,
Excel, or Markdown and include them in your reports.
Thanks for the amazingly quick response! As always, you guys are the best of any of the companies I have to/get to deal with!
— Tom Durkin
Department of Political Science, University of South Carolina
Intuitive and easy to use.
Once you learn the syntax of one estimator, graphics command,
or data management tool, you will effortlessly understand the rest.
Accuracy and reliability.
Stata is extensively and continually tested. Stata's tests produce
approximately 5.8 million lines of output. Each of those lines is
compared against known-to-be-accurate results
across editions of Stata and every operating system Stata supports to
ensure accuracy and reproducibility.
One package. No modules.
When you buy Stata, you obtain
everything for your statistical,
graphical, and data analysis needs. You do not need to buy separate modules
or import your data to specialized software.
Write your own Stata programs.
You can easily write your own Stata programs and commands. Share them
with others or use them to simplify your work. Utilize Stata's
do-files, ado-files, and Mata: Stata's own advanced programming
language that adds direct support for matrix programming. You can also
access and benefit from the thousands of existing Stata
community-contributed programs.
Extensive documentation.
Stata offers 35 manuals with more than 18,000 pages of PDF documentation
containing detailed examples, in-depth discussions, references to relevant literature,
and methods and formulas. Stata's documentation is a great place to learn about
Stata and the statistics, graphics, data management, and data science tools you
are using for your research.
Top-notch technical support.
Stata's technical support is known for their prompt, accurate,
detailed, and clear responses. People answering your questions have master's
and PhD degrees in relevant areas of research.
Join us for one of our free live webinars. Ready. Set. Go Stata shows you how to quickly get started manipulating, graphing, and analyzing your data. Or, go deeper in one of our special-topics webinars.
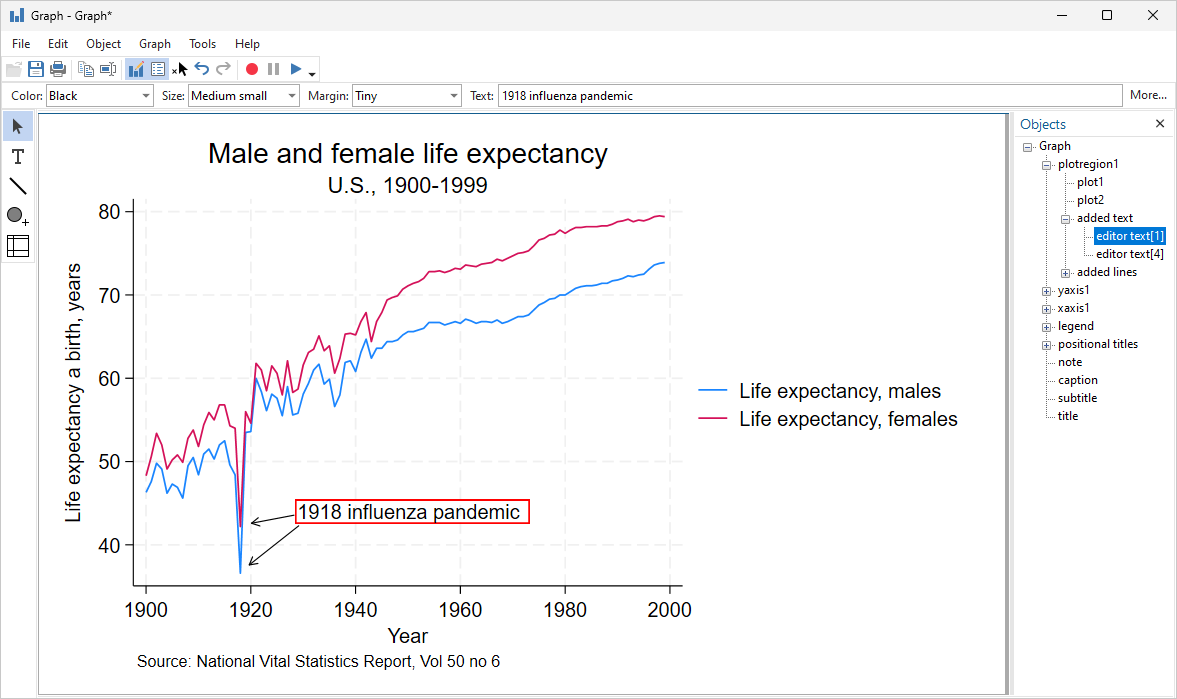
Stata's YouTube has over 300 videos with a dedicated playlist of methodologies important to political scientists. And they are a convenient teaching aid in the classroom.
Get started quickly at using Stata effectively, or even learn how to perform rigorous time-series, panel-data, or survival analysis, all from the comfort of you home or office. NetCourses make it easy.
Stata Press offers books with clear, step-by-step examples that make teaching easier and that enable students to learn and political scientists to implement the latest best practices in analysis.